概诉
本文转自 redis 的设计与实现
SDS
SDS 简介
Redis 没有直接使用 C 语言传统的字符串表示(以空字符结尾的字符数组,以下简称 C 字符串), 而是自己构建了一种名为简单动态字符串(simple dynamic string,SDS)的抽象类型, 并将 SDS 用作 Redis 的默认字符串表示。
举个例子, 如果客户端执行命令:
1 | SET msg "hello world" |
SDS 结构
1 | typedef char *sds; |
图 2-1 展示了一个 SDS 示例:
- free 属性的值为 0 , 表示这个 SDS 没有分配任何未使用空间。
- len 属性的值为 5 , 表示这个 SDS 保存了一个五字节长的字符串。
- buf 属性是一个 char 类型的数组, 数组的前五个字节分别保存了 ‘R’ 、 ‘e’ 、 ‘d’ 、 ‘i’ 、 ‘s’ 五个字符, 而最后一个字节则保存了空字符 ‘\0’ 。
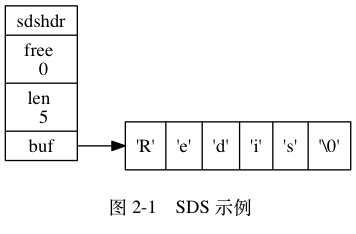
图 2-2 展示了另一个 SDS 示例:
- 这个 SDS 和之前展示的 SDS 一样, 都保存了字符串值 “Redis” 。
- 这个 SDS 和之前展示的 SDS 的区别在于, 这个 SDS 为 buf 数组分配了五字节未使用空间, 所以它的 free 属性的值为 5 (图中使用五个空格来表示五字节的未使用空间)。

SDS 结构与C字符串的不同
常数获取字符串长度
由于结构当中已经存贮了字符串的长度,所以当需要获取字符串长度的时候,直接返回,时间复杂度O(1)。
杜绝缓冲去溢出
与 C 字符串不同, SDS 的空间分配策略完全杜绝了发生缓冲区溢出的可能性
当 SDS API 需要对 SDS 进行修改时, API 会先检查 SDS 的空间是否满足修改所需的要求, 如果不满足的话, API 会自动将 SDS 的空间扩展至执行修改所需的大小, 然后才执行实际的修改操作, 所以使用 SDS 既不需要手动修改 SDS 的空间大小, 也不会出现前面所说的缓冲区溢出问题。
减少字符串修改的分配次数
正如前两个小节所说, 因为 C 字符串并不记录自身的长度, 所以对于一个包含了 N 个字符的 C 字符串来说, 这个 C 字符串的底层实现总是一个 N+1 个字符长的数组(额外的一个字符空间用于保存空字符)。
因为 C 字符串的长度和底层数组的长度之间存在着这种关联性, 所以每次增长或者缩短一个 C 字符串, 程序都总要对保存这个 C 字符串的数组进行一次内存重分配操作:
-
如果程序执行的是增长字符串的操作, 比如拼接操作(append), 那么在执行这个操作之前, 程序需要先通过内存重分配来扩展底层数组的空间大小 —— 如果忘了这一步就会产生缓冲区溢出。
-
如果程序执行的是缩短字符串的操作, 比如截断操作(trim), 那么在执行这个操作之后, 程序需要通过内存重分配来释放字符串不再使用的那部分空间 —— 如果忘了这一步就会产生内存泄漏。
为了减少空间分配的性能消耗,redis有一下集中策略来管理空间分配
空间预分配
空间预分配用于优化 SDS 的字符串增长操作: 当 SDS 的 API 对一个 SDS 进行修改, 并且需要对 SDS 进行空间扩展的时候, 程序不仅会为 SDS 分配修改所必须要的空间, 还会为 SDS 分配额外的未使用空间。
其中, 额外分配的未使用空间数量由以下公式决定:
-
如果对 SDS 进行修改之后, SDS 的长度(也即是 len 属性的值)将小于 1 MB , 那么程序分配和 len 属性同样大小的未使用空间, 这时 SDS len 属性的值将和 free 属性的值相同。
举个例子, 如果进行修改之后, SDS 的 len 将变成 13 字节, 那么程序也会分配 13 字节的未使用空间, SDS 的 buf 数组的实际长度将变成 13 + 13 + 1 = 27 字节(额外的一字节用于保存空字符)。
-
如果对 SDS 进行修改之后, SDS 的长度将大于等于 1 MB , 那么程序会分配 1 MB 的未使用空间。
举个例子, 如果进行修改之后, SDS 的 len 将变成 30 MB , 那么程序会分配 1 MB 的未使用空间, SDS 的 buf 数组的实际长度将为 30 MB + 1 MB + 1 byte 。
通过空间预分配策略, Redis 可以减少连续执行字符串增长操作所需的内存重分配次数。
惰性空间释放
惰性空间释放用于优化 SDS 的字符串缩短操作: 当 SDS 的 API 需要缩短 SDS 保存的字符串时, 程序并不立即使用内存重分配来回收缩短后多出来的字节, 而是使用 free 属性将这些字节的数量记录起来, 并等待将来使用。
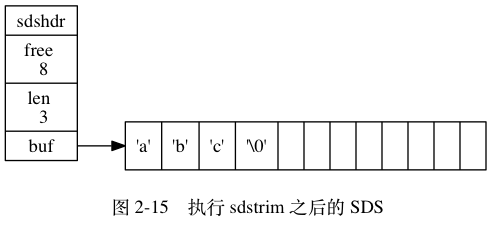
举个例子, sdstrim 函数接受一个 SDS 和一个 C 字符串作为参数, 从 SDS 左右两端分别移除所有在 C 字符串中出现过的字符。
比如对于图 2-14 所示的 SDS 值 s 来说, 执行:
1 | sdstrim(s, "XY"); // 移除 SDS 字符串中的所有 'X' 和 'Y' |

二进制安全
所有 SDS API 都会以处理二进制的方式来处理 SDS 存放在 buf 数组里的数据, 程序不会对其中的数据做任何限制、过滤、或者假设 —— 数据在写入时是什么样的, 它被读取时就是什么样。
这也是我们将 SDS 的 buf 属性称为字节数组的原因 —— Redis 不是用这个数组来保存字符, 而是用它来保存一系列二进制数据。
比如说, 使用 SDS 来保存之前提到的特殊数据格式就没有任何问题, 因为 SDS 使用 len 属性的值而不是空字符来判断字符串是否结束.
SDS API
| 函数 | 作用 | 时间复杂度 |
|---|---|---|
sdsnew |
创建一个包含给定 C 字符串的 SDS 。 | O(N) , N 为给定 C 字符串的长度。 |
sdsempty |
创建一个不包含任何内容的空 SDS 。 | O(1) |
sdsfree |
释放给定的 SDS 。 | O(1) |
sdslen |
返回 SDS 的已使用空间字节数。 | 这个值可以通过读取 SDS 的 len 属性来直接获得,
复杂度为 O(1) 。 |
sdsavail |
返回 SDS 的未使用空间字节数。 | 这个值可以通过读取 SDS 的 free 属性来直接获得,
复杂度为 O(1) 。 |
sdsdup |
创建一个给定 SDS 的副本(copy)。 | O(N) , N 为给定 SDS 的长度。 |
sdsclear |
清空 SDS 保存的字符串内容。 | 因为惰性空间释放策略,复杂度为 O(1) 。 |
sdscat |
将给定 C 字符串拼接到 SDS 字符串的末尾。 | O(N) , N 为被拼接 C 字符串的长度。 |
sdscatsds |
将给定 SDS 字符串拼接到另一个 SDS 字符串的末尾。 | O(N) , N 为被拼接 SDS 字符串的长度。 |
sdscpy |
将给定的 C 字符串复制到 SDS 里面, 覆盖 SDS 原有的字符串。 | O(N) , N 为被复制 C 字符串的长度。 |
sdsgrowzero |
用空字符将 SDS 扩展至给定长度。 | O(N) , N 为扩展新增的字节数。 |
sdsrange |
保留 SDS 给定区间内的数据, 不在区间内的数据会被覆盖或清除。 | O(N) , N 为被保留数据的字节数。 |
sdstrim |
接受一个 SDS 和一个 C 字符串作为参数, 从 SDS 左右两端分别移除所有在 C 字符串中出现过的字符。 | O(M*N) , M 为 SDS 的长度,
N 为给定 C 字符串的长度。 |
sdscmp |
对比两个 SDS 字符串是否相同。 | O(N) , N 为两个 SDS 中较短的那个 SDS
的长度。 |
链表
链表结构
每个链表节点使用一个 adlist.h/listNode 结构来表示:
1 | typedef struct listNode { |
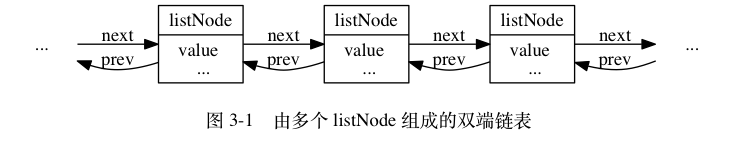
多个 listNode 可以通过 prev 和 next 指针组成双端链表, 如图 3-1 所示。
虽然仅仅使用多个 listNode 结构就可以组成链表, 但使用 adlist.h/list 来持有链表的话, 操作起来会更方便:
1 | typedef struct list { |
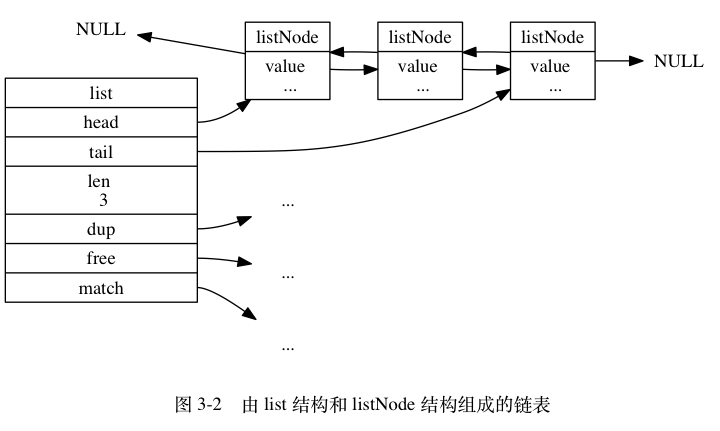
list 结构为链表提供了表头指针 head 、表尾指针 tail , 以及链表长度计数器 len , 而 dup 、 free 和 match 成员则是用于实现多态链表所需的类型特定函数:
- dup 函数用于复制链表节点所保存的值;
- free 函数用于释放链表节点所保存的值;
- match 函数则用于对比链表节点所保存的值和另一个输入值是否相等。
图 3-2 是由一个 list 结构和三个 listNode 结构组成的链表:
链表API
| 函数 | 作用 | 时间复杂度 |
|---|---|---|
listSetDupMethod |
将给定的函数设置为链表的节点值复制函数。 | O(1) 。 |
listGetDupMethod |
返回链表当前正在使用的节点值复制函数。 | 复制函数可以通过链表的 dup 属性直接获得,
O(1) |
listSetFreeMethod |
将给定的函数设置为链表的节点值释放函数。 | O(1) 。 |
listGetFree |
返回链表当前正在使用的节点值释放函数。 | 释放函数可以通过链表的 free 属性直接获得,
O(1) |
listSetMatchMethod |
将给定的函数设置为链表的节点值对比函数。 | O(1) |
listGetMatchMethod |
返回链表当前正在使用的节点值对比函数。 | 对比函数可以通过链表的 match
属性直接获得,
O(1) |
listLength |
返回链表的长度(包含了多少个节点)。 | 链表长度可以通过链表的 len 属性直接获得,
O(1) 。 |
listFirst |
返回链表的表头节点。 | 表头节点可以通过链表的 head 属性直接获得,
O(1) 。 |
listLast |
返回链表的表尾节点。 | 表尾节点可以通过链表的 tail 属性直接获得,
O(1) 。 |
listPrevNode |
返回给定节点的前置节点。 | 前置节点可以通过节点的 prev 属性直接获得,
O(1) 。 |
listNextNode |
返回给定节点的后置节点。 | 后置节点可以通过节点的 next 属性直接获得,
O(1) 。 |
listNodeValue |
返回给定节点目前正在保存的值。 | 节点值可以通过节点的 value 属性直接获得,
O(1) 。 |
listCreate |
创建一个不包含任何节点的新链表。 | O(1) |
listAddNodeHead |
将一个包含给定值的新节点添加到给定链表的表头。 | O(1) |
listAddNodeTail |
将一个包含给定值的新节点添加到给定链表的表尾。 | O(1) |
listInsertNode |
将一个包含给定值的新节点添加到给定节点的之前或者之后。 | O(1) |
listSearchKey |
查找并返回链表中包含给定值的节点。 | O(N) , N 为链表长度。 |
listIndex |
返回链表在给定索引上的节点。 | O(N) , N 为链表长度。 |
listDelNode |
从链表中删除给定节点。 | O(1) 。 |
listRotate |
将链表的表尾节点弹出,然后将被弹出的节点插入到链表的表头, 成为新的表头节点。 | O(1) |
listDup |
复制一个给定链表的副本。 | O(N) , N 为链表长度。 |
listRelease |
释放给定链表,以及链表中的所有节点。 | O(N) , N 为链表长度。 |
赞赏一下