概述
在大多数的情况下,我们需要对一个共享资源进行写操作,在分布式的环境下,对于资源的写操作的互斥性就显得尤为重要。由于生产环境对redis有很多依赖,所以最近在分布式锁的实现上进行了一些调研。
对于锁的安全性,一直是分布式领域不可逃避的话题,一个分布式锁的实现在网上所以下,就会发现,这些文章的思路大体相近,给出的实现算法也看似合乎逻辑,但当我们着手去实现它们的时候,却发现如果你越是仔细推敲,疑虑也就越来越多。
关于Redis分布式锁的安全性问题,在分布式系统专家Martin Kleppmann和Redis的作者antirez之间就发生过一场争论。由于对这个问题一直以来比较关注,所以我前些日子仔细阅读了与这场争论相关的资料。这场争论的大概过程是这样的:为了规范各家对基于Redis的分布式锁的实现,Redis的作者提出了一个更安全的实现,叫做Redlock。有一天,Martin Kleppmann写了一篇blog,分析了Redlock在安全性上存在的一些问题。
本文结合redsiion 的对分布式锁的单点的实现机制,在结合集群下的Redlock的实现机制,分析一下分布式锁在现阶段出现的问题。
基于单Redis节点的分布式锁
一、Redisson的简单应用
Redisson的官网,看看如何在项目中引入Redisson的依赖,然后基于Redis实现分布式锁的加锁与释放锁。下面给大家看一段简单的使用代码片段,先直观的感受一下:
1 | RLock lock = redisson.getLock("myLock"); |
二、Redisson实现Redis分布式锁的底层原理
好的,接下来就通过一张手绘图,给大家说说Redisson这个开源框架对Redis分布式锁的实现原理。
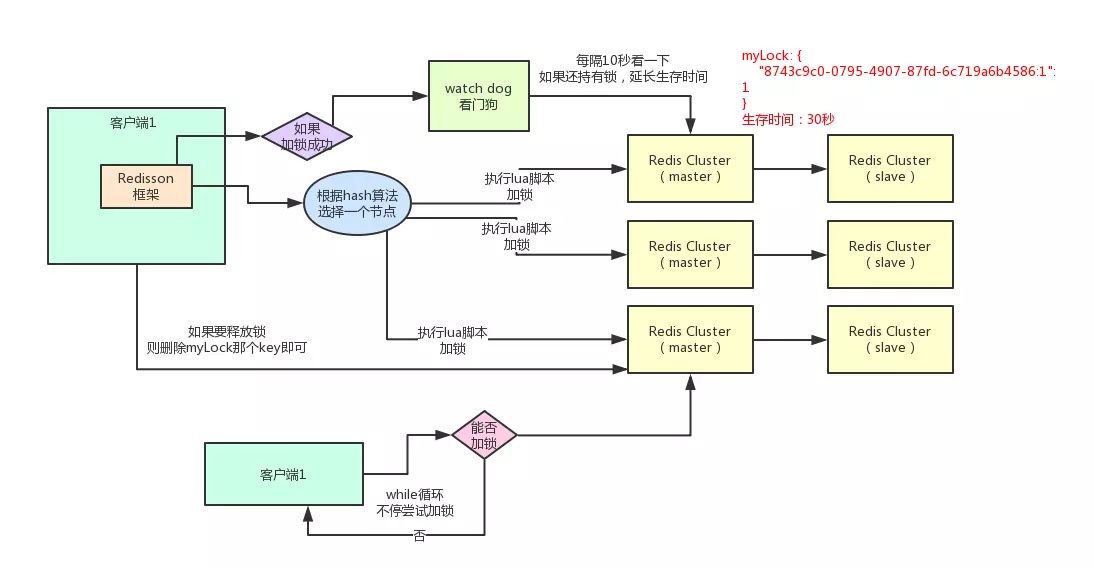
(1)加锁机制
如果该客户端面对的是一个redis cluster集群,他首先会根据hash节点选择一台机器。这里注意,仅仅只是选择一台机器!这点很关键!紧接着,就会发送一段lua脚本到redis上,因为可以通过封装在lua脚本中发送给redis,保证这段复杂业务逻辑执行的原子性。那段lua脚本如下所示:
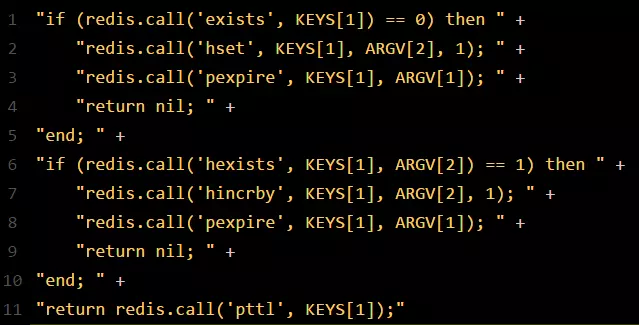
那么,这段lua脚本是什么意思呢?这里KEYS[1]代表的是你加锁的那个key,比如说:
1 | RLock lock = redisson.getLock("myLock"); |
这里你自己设置了加锁的那个锁key就是myLock。
ARGV[1]代表的就是锁key的默认生存时间,默认30秒。
ARGV[2]代表的是加锁的客户端的ID,类似于下面这样:
8743c9c0-0795-4907-87fd-6c719a6b4586:1
给大家解释一下,第一段if判断语句,就是用“exists myLock”命令判断一下,如果你要加锁的那个锁key不存在的话,你就进行加锁。如何加锁呢?很简单,用下面的命令:hset myLock
8743c9c0-0795-4907-87fd-6c719a6b4586:1 1,通过这个命令设置一个hash数据结构,这行命令执行后,会出现一个类似下面的数据结构:
1 | mylock: |
上述就代表“8743c9c0-0795-4907-87fd-6c719a6b4586:1”这个客户端对“myLock”这个锁key完成了加锁。接着会执行“pexpire myLock 30000”命令,设置myLock这个锁key的生存时间是30秒。
这里一定要增加一个myLock的生存时间。否则的话,当一个客户端获取锁成功之后,假如它崩溃了,或者由于发生了网络分割(network partition)导致它再也无法和Redis节点通信了,那么它就会一直持有这个锁,而其它客户端永远无法获得锁了。
(2)锁互斥机制
那么在这个时候,如果客户端2来尝试加锁,执行了同样的一段lua脚本,会咋样呢?很简单,第一个if判断会执行“exists myLock”,发现myLock这个锁key已经存在了。接着第二个if判断,判断一下,myLock锁key的hash数据结构中,是否包含客户端2的ID,但是明显不是的,因为那里包含的是客户端1的ID。
所以,客户端2会获取到pttl myLock返回的一个数字,这个数字代表了myLock这个锁key的剩余生存时间。比如还剩15000毫秒的生存时间。此时客户端2会进入一个while循环,不停的尝试加锁。
(3)watch dog自动延期机制
客户端1加锁的锁key默认生存时间才30秒,如果超过了30秒,客户端1还想一直持有这把锁,怎么办呢?
简单!只要客户端1一旦加锁成功,就会启动一个watch dog看门狗,他是一个后台线程,会每隔10秒检查一下,如果客户端1还持有锁key,那么就会不断的延长锁key的生存时间。
(4)可重入加锁机制
那如果客户端1都已经持有了这把锁了,结果可重入的加锁会怎么样呢?比如下面这种代码:
1 | RLock lock = redisson.getLock("myLock"); |
这时我们来分析一下上面那段lua脚本。第一个if判断肯定不成立,“exists myLock”会显示锁key已经存在了。第二个if判断会成立,因为myLock的hash数据结构中包含的那个ID,就是客户端1的那个ID,也就是“8743c9c0-0795-4907-87fd-6c719a6b4586:1”
此时就会执行可重入加锁的逻辑,他会用:
incrby myLock 8743c9c0-0795-4907-87fd-6c71a6b4586:1 1 ,通过这个命令,对客户端1的加锁次数,累加1。此时myLock数据结构变为下面这样:
1 | mylock: |
大家看到了吧,那个myLock的hash数据结构中的那个客户端ID,就对应着加锁的次数
(5)释放锁机制
如果执行lock.unlock(),就可以释放分布式锁,此时的业务逻辑也是非常简单的。其实说白了,就是每次都对myLock数据结构中的那个加锁次数减1。如果发现加锁次数是0了,说明这个客户端已经不再持有锁了,此时就会用:“del myLock”命令,从redis里删除这个key。然后呢,另外的客户端2就可以尝试完成加锁了。这就是所谓的分布式锁的开源Redisson框架的实现机制。
一般我们在生产系统中,可以用Redisson框架提供的这个类库来基于redis进行分布式锁的加锁与释放锁。
(6)上述Redis分布式锁的缺点
其实上面那种方案最大的问题,就是如果你对某个redis master实例,写入了myLock这种锁key的value,此时会异步复制给对应的master slave实例。但是这个过程中一旦发生redis master宕机,主备切换,redis slave变为了redis master。
接着就会导致,客户端2来尝试加锁的时候,在新的redis master上完成了加锁,而客户端1也以为自己成功加了锁。此时就会导致多个客户端对一个分布式锁完成了加锁。这时系统在业务语义上一定会出现问题,导致各种脏数据的产生。
所以这个就是redis cluster,或者是redis master-slave架构的主从异步复制导致的redis分布式锁的最大缺陷:在redis master实例宕机的时候,可能导致多个客户端同时完成加锁。
基于分布式redis的RedLock 的分布式锁的实现机制
由于前面介绍的基于单Redis节点的分布式锁在failover的时候会产生解决不了的安全性问题,因此提出了新的分布式锁的算法Redlock,它基于N个完全独立的Redis节点(通常情况下N可以设置成5)。
运行Redlock算法的客户端依次执行下面各个步骤,来完成获取锁的操作:
加锁过程
- 获取当前时间(毫秒数)。
- 按顺序依次向N个Redis节点执行获取锁的操作。这个获取操作跟前面基于单Redis节点的获取锁的过程相同, 为了保证在某个Redis节点不可用的时候算法能够继续运行,这个获取锁的操作还有一个超时时间(time out),它要远小于锁的有效时间(几十毫秒量级)。客户端在向某个Redis节点获取锁失败以后,应该立即尝试下一个Redis节点。这里的失败,应该包含任何类型的失败,比如该Redis节点不可用,或者该Redis节点上的锁已经被其它客户端持有(注:Redlock原文中这里只提到了Redis节点不可用的情况,但也应该包含其它的失败情况)。
-
计算整个获取锁的过程总共消耗了多长时间,计算方法是用当前时间减去第1步记录的时间。如果客户端从大多数Redis节点(>= N/2+1)成功获取到了锁,并且获取锁总共消耗的时间没有超过锁的有效时间(lock validity time),那么这时客户端才认为最终获取锁成功;否则,认为最终获取锁失败。
-
如果最终获取锁成功了,那么这个锁的有效时间应该重新计算,它等于最初的锁的有效时间减去第3步计算出来的获取锁消耗的时间。
-
如果最终获取锁失败了(可能由于获取到锁的Redis节点个数少于N/2+1,或者整个获取锁的过程消耗的时间超过了锁的最初有效时间),那么客户端应该立即向所有Redis节点发起释放锁的操作(即前面介绍的Redis Lua脚本)。
设想这样一种情况,客户端发给某个Redis节点的获取锁的请求成功到达了该Redis节点,这个节点也成功执行了SET操作,但是它返回给客户端的响应包却丢失了。这在客户端看来,获取锁的请求由于超时而失败了,但在Redis这边看来,加锁已经成功了。因此,释放锁的时候,客户端也应该对当时获取锁失败的那些Redis节点同样发起请求。实际上,这种情况在异步通信模型中是有可能发生的:客户端向服务器通信是正常的,但反方向却是有问题的。
Redlock 出现的问题
崩溃重启
假设一共有5个Redis节点:A, B, C, D, E。设想发生了如下的事件序列:
- 客户端1成功锁住了A, B, C,获取锁成功(但D和E没有锁住)。
- 节点C崩溃重启了,但客户端1在C上加的锁没有持久化下来,丢失了。
- 节点C重启后,客户端2锁住了C, D, E,获取锁成功。
这样,客户端1和客户端2同时获得了锁(针对同一资源)。
延迟重启(delayed restarts) 的概念。
也就是说,一个节点崩溃后,先不立即重启它,而是等待一段时间再重启,这段时间应该大于锁的有效时间(lock validity time)。这样的话,这个节点在重启前所参与的锁都会过期,它在重启后就不会对现有的锁造成影响。
客户端长期阻塞导致锁过期
假设锁服务本身是没有问题的,它总是能保证任一时刻最多只有一个客户端获得锁。
客户端1在获得锁之后发生了很长时间的GC pause,在此期间,它获得的锁过期了,而客户端2获得了锁。当客户端1从GC pause中恢复过来的时候,它不知道自己持有的锁已经过期了,它依然向共享资源)发起了写数据请求,而这时锁实际上被客户端2持有,因此两个客户端的写请求就有可能冲突(锁的互斥作用失效了)。

系统环境太复杂,仍然有很多原因导致进程的pause,比如虚存造成的缺页故障(page fault),再比如CPU资源的竞争。即使不考虑进程pause的情况,网络延迟也仍然会造成类似的结果, 即客户端进程卡死的问题。
fencing token 解决方案
fencing token是一个单调递增的数字,当客户端成功获取锁的时候它随同锁一起返回给客户端。而客户端访问共享资源的时候带着这个fencing token,这样提供共享资源的服务就能根据它进行检查,拒绝掉延迟到来的访问请求(避免了冲突)。如下图
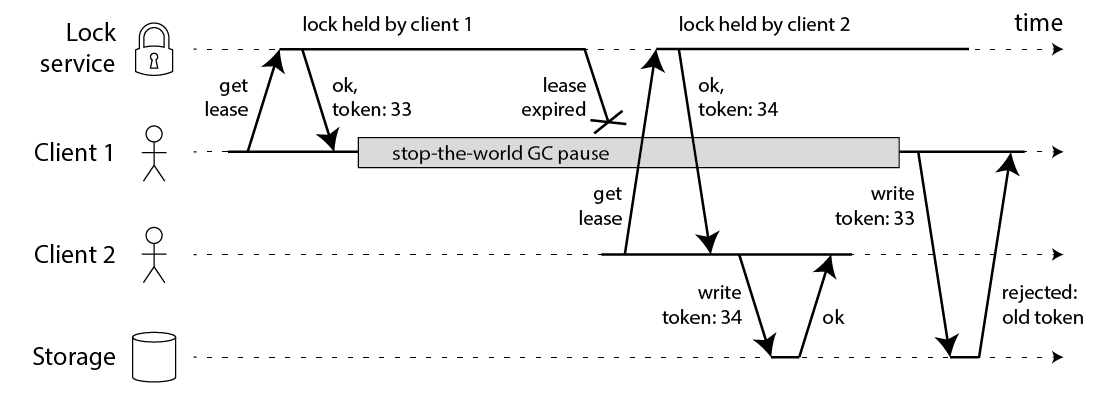
在上图中,客户端1先获取到的锁,因此有一个较小的fencing token,等于33,而客户端2后获取到的锁,有一个较大的fencing token,等于34。客户端1从GC pause中恢复过来之后,依然是向存储服务发送访问请求,但是带了fencing token = 33。存储服务发现它之前已经处理过34的请求,所以会拒绝掉这次33的请求。这样就避免了冲突。
时钟跳转以及网络延迟
对于时钟的过分依赖也将会导致redlock分布式锁的一些问题,首先给出了下面的两个例子(还是假设有5个Redis节点A, B, C, D, E):
-
时钟跳转
- 客户端1从Redis节点A, B, C成功获取了锁(多数节点)。由于网络问题,与D和E通信失败。
- 节点C上的时钟发生了向前跳跃,导致它上面维护的锁快速过期。
- 客户端2从Redis节点C, D, E成功获取了同一个资源的锁(多数节点)。
- 客户端1和客户端2现在都认为自己持有了锁。
-
网络延迟
- 客户端1向Redis节点A, B, C, D, E发起锁请求。
- 各个Redis节点已经把请求结果返回给了客户端1,但客户端1在收到请求结果之前进入了长时间的GC pause。
- 在所有的Redis节点上,锁过期了。
- 客户端2在A, B, C, D, E上获取到了锁。
- 客户端1从GC pause从恢复,收到了前面第2步来自各个Redis节点的请求结果。客户端1认为自己成功获取到了锁。
+客户端1和客户端2现在都认为自己持有了锁。
时钟跳跃的时候,举了两个可能造成时钟跳跃的具体例子:
- 系统管理员手动修改了时钟。
- 从NTP服务收到了一个大的时钟更新事件。
对于这个方面的解决是:
- 手动修改时钟这种人为原因,不要那么做就是了。否则的话,如果有人手动修改Raft协议的持久化日志,那么就算是Raft协议它也没法正常工作了。
- 使用一个不会进行“跳跃”式调整系统时钟的ntpd程序(可能是通过恰当的配置),对于时钟的修改通过多次微小的调整来完成。
另外一个是个网络延迟,网络延迟目前在分布式锁中没有较好的解决方案,即所有的分布式系统当中都将面临这个问题,而redlock的作者也明确表示过。
分布式锁的结论
在Martin的文章中,还有一个很有见地的观点,就是对锁的用途的区分。他把锁的用途分为两种:
-
为了效率(efficiency),协调各个客户端避免做重复的工作。即使锁偶尔失效了,只是可能把某些操作多做一遍而已,不会产生其它的不良后果。比如重复发送了一封同样的email。
-
为了正确性(correctness)。在任何情况下都不允许锁失效的情况发生,因为一旦发生,就可能意味着数据不一致(inconsistency),数据丢失,文件损坏,或者其它严重的问题。
最后,Martin得出了如下的结论: -
如果是为了效率(efficiency)而使用分布式锁,允许锁的偶尔失效,那么使用单Redis节点的锁方案就足够了,简单而且效率高。Redlock则是个过重的实现(heavyweight)。
-
如果是为了正确性(correctness)在很严肃的场合使用分布式锁,那么不要使用Redlock。它不是建立在异步模型上的一个足够强的算法,它对于系统模型的假设中包含很多危险的成分(对于timing)。而且,它没有一个机制能够提供fencing token。那应该使用什么技术呢?Martin认为,应该考虑类似Zookeeper的方案,或者支持事务的数据库。
参考链接
- 基于Redis的分布式锁到底安全吗(上)?
- 基于Redis的分布式锁到底安全吗(下)?
- how to do distributed lockin
- Distributed Locking with Redis
赞赏一下