基础
所谓读写锁,是对访问资源共享锁和排斥锁,一般的重入性语义为:如果对资源加了写锁,其他线程无法再获得写锁与读锁,但是持有写锁的线程,可以对资源加读锁(锁降级);如果一个线程对资源加了读锁,其他线程可以继续加读锁。本文主要分析JDK(1.8+)JCU包中读写锁接口(ReadWriteLock)的重要实现类ReentrantReadWriteLock的细节,来阐述AQS的应用。
样例
我们来看一段例子
1 | public class ReentrantReadWriteLockExample { |
运行结果如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
211 -->读数据:0.0
2 -->读数据:0.0
0 -->读数据:0.0
4 -->读数据:0.0
3 -->读数据:0.0
6 -->读数据:0.0
5 -->读数据:0.0
7 -->读数据:0.0
8 -->读数据:0.0
9 -->读数据:0.0
写数据: 10.0
sleep: ...wake up ... 10 -->读数据:10.0
11 -->读数据:10.0
12 -->读数据:10.0
13 -->读数据:10.0
14 -->读数据:10.0
15 -->读数据:10.0
17 -->读数据:10.0
19 -->读数据:10.0
16 -->读数据:10.0
18 -->读数据:10.0
结论,我们可以看到,读写锁互斥的,当有写锁锁住资源的时候,无法进行读取,同理,当有数据加了读锁,无法进行写入。
源码分析
类图
看一下
ReentrantReadWriteLock的继承类图
我们可以发现 ReentrantReadWriteLock类继承了读写锁 ReadWriteLock 的接口:
1 | public interface ReadWriteLock { |
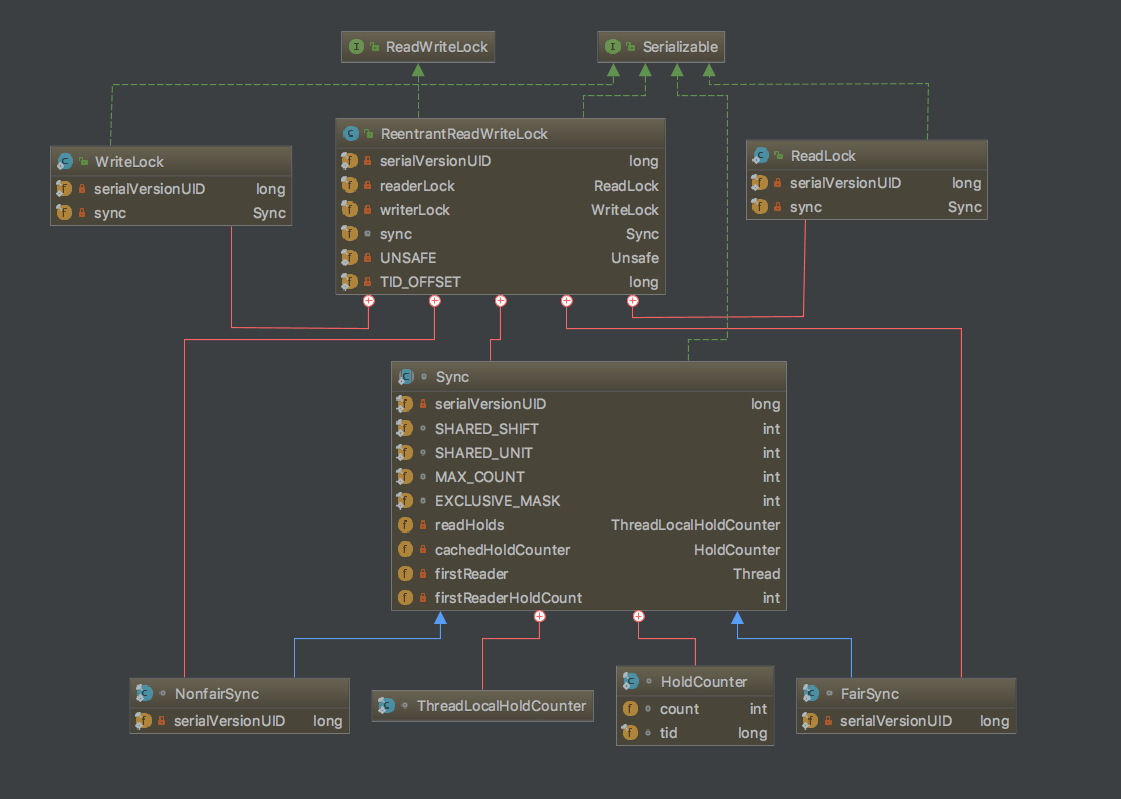
- 我们来看整体的类图
ReentrantReadWriteLock 构造函数
1 | public class ReentrantReadWriteLock implements ReadWriteLock, java.io.Serializable { |
ReentrantReadWriteLock中提供了两把锁分别是 ReadLock (读锁)和 WriterLock(写锁),这两个锁都是以内部类的形式存在的。这两个内部类当中有都有一个 Sync的对象,这个对象正是AbstractQueuedSynchronizer (AQS)的实现类。锁中的 Sync 的对象和 ReentrantReadWriteLock 对象中的Sync是同一个对象。 在ReentrantReadWriteLock的构造函数中,这个对象对根据我们锁填参数分为 FairSync (公平锁)和 NonfairSync (非公平锁)。其中 FairSync 和 NonfairSync 都有各自的实现,下文会分析。
锁(ReadLock 和 WriteLock)之间的关系
读锁和写锁有以下特点:
1)
writeLock是排他的exclusive,readLock是共享的sahred。2) 同一个线程可以拥有
writeLock与readLock(但必须先获取writeLock再获取readLock, 反过来进行获取会导致死锁)。writeLock与readLock是互斥的(就像Mysql的X S锁)。(死锁的问题后面会具体分析)3) 在获取
writeLock时监测到有线程获取了readLock, 则获取writeLock是线程会一直在AQS的sync queue里面等待readLock被完全释放, 而若获取readLock的时候,若这个线程以前获取过readLock, 则还能继续重入 (reentrant), 而没有获取readLock的线程因为AQS Sync Queue里面有想要获取writeLock的 线程创建的Node节点存在, 会存放在AQS Sync Queue队列里面 一直block。
如果线程想要获取readLock,并且成功获取,那么前提是aqs队列中没有writeLock对应的Node, 如果线程想要获取writeLock,并且成功获取,那么前提是aqs队列中没有readLock对应的Node,
如果你不知道什么是
Node和AQS Sync Queue队列,可以参考我的另外两篇博文:JAVA多线程之AQS分析(1),JAVA多线程之AQS分析(2)
Sync 类详解
ReentrantReadWriterLock 同样使用自己的内部类 Sync(继承 AbstractQueuedSynchronizer )实现CLH算法。为了方便对读写锁获取机制的了解,先介绍一下Sync内部类中几个属性。
对于CLH 锁,这里就不在展开,有兴趣的小伙伴可以自行查阅。
CLH lock is Craig, Landin, and Hagersten (CLH) locks, CLH lock is a spin lock, can ensure no hunger, provide fairness first come first service.
The CLH lock is a scalable, high performance, fairness and spin lock based on the list, the application thread spin only on a local variable, it constantly polling > the precursor state, if it is found that the pre release lock end spin.
Sync 属性
1 |
|
- 首先
ReentrantReadWriterLock使用一个32位的int类型来表示锁被占用的线程数(state这个字段在ReentrantLock中代表同一个线程的加锁次数,采取的办法是,高16位用来表示读锁占有的线程数量,用低16位表示写锁被同一个线程申请的次数。这里留一个疑问,就是为什么要保存同一个线程的申请次数
Sync 状态(静态变量的含义)
state: 这个是在AQS的类中定义的,并没有在ReentrantReadWriteLock类的Sync单独实现,表示了当前锁的状态。SHARED_SHIFT: 对32位的int进行分割 (对半 16)SHARED_SHIFT,表示读锁占用的位数,常量16, 也就是对上文的status字段表示分割。SHARED_UNIT: 如果增加一个读锁,按照上述设计,就相当于增加SHARED_UNIT,其中的值为000000000 00000001 00000000 00000000。我们可以看到他的含义就是 将int的高16位作为一个单元,然后在这个单元上加上这个单元的1。MAX_COUNT: 表示申请读锁最大的线程数量,为65535。例:000000000 00000000 11111111 11111111。EXCLUSIVE_MASK:表示计算写锁的值使用的掩码,该值为15个1,用getState()&EXCLUSIVE_MASK算出写锁的线程数。举例说明
现在当前,申请读锁的线程数为13个,写锁一个,那
state怎么表示?
用一个32位的int类型的高16位表示读锁线程数,13的二进制为1101,那state的二进制表示为00000000 00001101 00000000 00000001十进制数为851969, 接下来要得到读锁和写锁的数量时,需要根据这个851968这个值得出上文中的 13 与 1。要算成13,只需要将state无符号向左移位16位置,得出00000000 00001101,就出13,根据851969要算成低16位置,只需要用该00000000 00001101 00000000 00000001&111111111111111(15位),就可以得出00000001,就是利用了1&1得1,1&0得0这个技巧。
ReadLock
我们来看一下读锁的源码
核心代码
1 | public static class ReadLock implements Lock, java.io.Serializable { |
加锁的方法为获取
1 | // sync 的获取共享锁的方法 |
看完这段代码有几个问题:
- 第一:为什么要记录第一把读锁
firstReader? - 第二:
cachedHoldCounter是干什么用的? - 第三:排队的阻塞策略是什么?
- 第四:
fullTryAcquireShared这个方法是干什么用的,为什么保底要执行这个方法? - 第五:加锁之前为什么要
tryAcquireShared为什么不能直接加锁么,之后doAcquireShared方法是做什么,为什么要有这一步?
带着这几个问题,我们往下看
readHolds 类(cachedHoldCounter 作用)
- 首先来解决第二个问题
cachedHoldCounter是干什么用的?
在Sync类当中有这么几个参数
1 | static final class HoldCounter { |
读写锁是要给多个线程调用的,也就是说,多个线程会同事操作同一个对象,每个线程如果读锁重入,就要记住没个线程对应重入了多少读锁。HoldCounter 相当于一个计数器。一次共享锁的操作就相当于在该计数器的操作。获取共享锁,则该计数器 + 1,释放共享锁,该计数器 - 1。只有当线程获取共享锁后才能对共享锁进行释放、重入操作。所以 HoldCounter 的作用就是当前线程持有共享锁的数量,这个数量必须要与线程绑定在一起,否则操作其他线程锁就会抛出异常。
HoldCounter 定义非常简单,就是一个计数器 count 和线程 tid两个变量。按照这个意思我们看到 HoldCounter 是需要和某给线程进行绑定了,我们知道如果要将一个对象和线程绑定仅仅有 tid 是不够的,而且从上面的代码我们可以看到 HoldCounter 仅仅只是记录了tid,根本起不到绑定线程的作用。那么怎么实现呢?答案是 ThreadLocal, 定义如下:
- ThradLocalHoldCounter 计数器
ThradLocalHoldCounter 继承了ThreadLocal,将 HoldCounter 绑定到当前线程上,同时 HoldCounter 也持有线程Id,这样在释放锁的时候才能知道 ReadWriteLock 里面缓存的上一个读取线程(cachedHoldCounter) 是否是当前线程。这样做的好处是可以减少 ThreadLocal.get()的次数,因为这也是一个耗时操作。需要说明的是这样 HoldCounter 绑定线程id而不绑定线程对象的原因是避免HoldCounter 和 ThreadLocal互相绑定而GC难以释放它们(尽管GC能够智能的发现这种引用而回收它们,但是这需要一定的代价),所以其实这样做只是为了帮助GC快速回收对象而已。
- 为什么要记录第一把读锁
firstReader?
其实这个很好理解,有了上面 cachedHoldCounter 的解释,这里的 firstReader 第一个获取锁的线程也就好理解,一个是最后一个获取锁的线程,一个是第一个获取读锁的线程,这样做的目的就是为了性能考虑,实际上就是缓存。因为第一个和最后一个读锁在整个互斥链上有着比较重要的作用,在后边的代码中,我们可以看到他们的实际作用。
fullTryAcquireShared 自旋效应
齐次,fullTryAcquireShared 这个方法是干什么用的,为什么保底要执行这个方法??
我们来看一下代码
1 | final int fullTryAcquireShared(Thread current) { |
看代码发现,这段代码和 tryAcquireShared 特别相似,相对于其,多加了一些额外的判断和一个for循环。从tryAcquireShared 中可以看到,调用到该方法的前提是:
1 | if (!readerShouldBlock() &&r < MAX_COUNT && |
- 1、
readerShouldBlock失败,证明当前有写锁,失败。 - 2、
compareAndSetState失败,证明当前可能有读锁被抢占。
有读写锁的特性可以得到,读锁之间是可以重入的。那么如果这两个有任意一个调用失败,我们都可以进行再次的尝试.如果再次尝试,写锁释放,我们既可以得到锁。compareAndSetState 失败,我们也可以再次尝试。当有上面两个条件任意一个失败的时候,我们让这个方法进入自旋状态,确保读锁可以有效的获取锁。
锁降级
在这段代码之前 我们还可以看到
1 | // 这段代码的含义是,如果当前线程拥有写锁,但是又要去申请写锁,是允许的当写锁被持有时, |
锁降级定义:重入还允许从写入锁降级为读取锁,其实现方式是:先获取写入锁,然后获取读取锁,最后释放写入锁。但是,从读取锁升级到写入锁是不可能的。
锁降级的必要性
我们来看一下这样的情景, 如果读锁不在写锁之后 进行降级 那么情况1 中的 线程获取和修改的值就会出现类脏读的问题
线程1 命名修改了 data = 1 但是由于 写锁后没有降级成读锁,导致data 被线程2 改成了 2
| 时间序列 | 线程1 | 线程2 |
|---|---|---|
| 获取写锁 | ||
| 更改数据 data = 1 | ||
| 释放写锁 | 获取写锁 | |
| data =2 | ||
| 处理数据 | ||
| 释放写锁 | ||
| 处理完毕 | ||
| 打印data = 2 | ||
| 打印data = 2 |
读锁降级为写锁
| 时间序列 | 线程1 | 线程2 |
|---|---|---|
| 获取写锁 | ||
| 获得读锁 | ||
| 更改数据 data = 1 | ||
| 释放写锁 | ||
| 获取写锁失败 阻塞 | ||
| 处理数据 | ||
| 处理完毕 | ||
| 打印data = 2 | ||
| 释放读锁 | 获取写锁 成功 |
doAcquireShared 正式加锁
若发现当前的线程应该排队的时候,那么会正式进入以下代码,用于加锁。代码 和 acquireQueued 比较相似,可以参考 JAVA多线程之AQS分析(2)-Sync doAcquireSharedInterruptibly
这里只贴一下代码
1 | private void doAcquireShared(int arg) { |
ReadLockUnlock 解锁流程
核心代码
1 | // ReentrantReadWriteLock 代码 |
由代码我们知道,其实就只是做了状态的更改,更改statue 和每个线程的holder的数量,具体的解锁流程代码如下:
1 | private void doReleaseShared() { |
doReleaseShared 的方法 在JAVA多线程之AQS分析(2)-sync-doReleaseshared 有详细的介绍
这里再次强调一下
这里为什么要 拿到head?:因为共享锁是可以传播的,意思是如果某一个共享锁阻塞的线程被唤醒了,那么意味着排队链上的所有被共享节点阻塞的线程都应该被唤醒。
如果当前线程是排队链的第n个,那么当被唤醒的时候,我们要找到头部节点,如果头结点是阻塞状态,那么自旋的去获取 ,知道解锁成功,将head链唤醒,当head被唤醒的时候,会执行
setHeadAndPropagate这个方法,然后唤醒下一个被共享锁阻塞的线程。如果头结点是当前线程,那就意味着头结点已经被唤醒了或者已经持有锁了,那么意味着已经做过唤醒其他的(
setHeadAndPropagate)操作了。如果头结点是阻塞状态,那么自旋的去获取 ,知道解锁成功
至此,我们已经完整了解了读写锁的加锁流程。 那么我们剩下一个问题,就是:排队的策略是什么样子的? 这就涉及到我们的写锁流程
WriteLock
按照我们的传统,来看一下代码1
2
3
4
5
6
7
8
9public void lock() {
sync.acquire(1);
}
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
从代码看到,加锁的流程会降级为普通排它锁,之所以可以这么做,完全可以无视上面的读写锁的互斥规则的原因就是,读锁的重入基本上是不会对阻塞链造成什么改变的,原因如下 在读锁tryAcquireShared 的方法有个readerShouldBlock 方法,这个方法是由公平锁和非公平锁的类实现的
1 | static final class FairSync extends Sync { |
排队的策略
- 公平锁的
readerShouldBlock/writerShouldBlock
首先来看公平锁的 block 判定都是 hasQueuedPredecessors 这个方法。 这个方法的判断标准我们以前讨论过,就是看排队链有没有节点,也就是说,只有写锁tryAcquire失败了(注意,tryAcquire != 0 证明 有读锁占据高位置) 才会加入到队列当中,那么意味着,一旦加入排队,往后的读锁就要执行 hasQueuedPredecessors 方法的时候,就要排队了。
writerShouldBlock也是一样,写锁要排到队列后边,两个写锁有先后关系。如下
1 | head(read) -> wl1(写锁1) -> rl1(读锁1) ... -> wl2(写锁2) ---> other |
非公平锁的
readerShouldBlock/writerShouldBlock: 非公平锁的排队策略 在注释生已经说的很清楚了,我们来看一下这两段注释As a heuristic to avoid indefinite writer starvation,
block if the thread that momentarily appears to be head
of queue, if one exists, is a waiting writer. This is
only a probabilistic effect since a new reader will not
block if there is a waiting writer behind other enabled
readers that have not yet drained from the queue.
Returns {@code true} if the apparent first queued thread, if one
exists, is waiting in exclusive mode. If this method returns
{@code true}, and the current thread is attempting to acquire in
shared mode (that is, this method is invoked from {@link
tryAcquireShared}) then it is guaranteed that the current thread
is not the first queued thread. Used only as a heuristic in
ReentrantReadWriteLock.
简单的来说就是,当代队里中的第一个节点(head 后的第一个节点 )不是共享锁的时候,需要排序。换句话说,当队列中(head 后第一个元素)是写锁的时候,且写锁被阻塞了,那么这个时候,读锁就要排队,因为读锁必须要排在写锁侯彪,看代码已经很清晰了。
1 | final boolean apparentlyFirstQueuedIsExclusive() { |
总结
致辞,AQS的核心已经全部分享完毕了。总结如下
- AQS的排最节点氛围 共享和排他两种模式,共享锁的唤醒是由前一个节点来唤醒。
- 排它锁的阻塞由阻塞线程完成,但是前一个排他锁的阻塞状态是由阻塞线程完成的。
- statue 不仅保存了读锁的数量,还保存了写锁的数量。
- 读锁可重入,一旦有写锁加入等待队列,意味着后面想要获取锁的操作(未获取过锁的)操作都需要排队。一旦写锁释放,后边的写锁就都会被唤醒。
参考
- ReentrantReadWriteLock 源码分析(基于Java 8)
- 【死磕Java并发】——-J.U.C之读写锁:ReentrantReadWriteLock
- 并发编程之——读锁源码分析(解释关于锁降级的争议)
赞赏一下