概诉 Keepalived 作用 keepalived顾名思义是保持存活,常用来搭建设备的高可用,防止业务核心设备出现单点故障。keepalived基于VRRP协议来实现高可用,主要用作realserver的健康检查以及负载均衡主机和backup主机之间的故障漂移。他很大程度上是为ipvs服务的,也不需要共享存储。Keepalived主要的任务就是去调用ipvsadm命令,来生成规则,并自动实现将用户需要访问的地址转移到可用LVS节点实现。所以keepalive的高可用是属于具有很强针对性的高可用。
Keepalived的主要目的就是它自身启动为一个服务,它工作在多个LVS主机节点上,当前活动的节点叫做Master备用节点叫做Backup,Master会不停的向Backup节点通告自己的心跳,这种通告是基于VRRP协议的。Backup节点一旦接收不到Master的通告信息,它就会把LVS的VIP拿过来,并且把ipvs的规则也拿过来,在自己身上生效,从而替代Master节点。
Keepalived除了可以监控和转移LVS资源之外,它还可以直接配置LVS而不需要直接使用ipvsadm命令,因为它可以调用,也就是说在LVS+KEEPALIVED模型中,你所有的工作在Keepalived中配置就可以了,而且它还有对后端应用服务器健康检查的功能。
如果有一台web服务器死机,或工作出现故障,Keepalived将检测到,并将有故障的服务器从系统中剔除,同时使用其他服务器代替该服务器的工作,当服务器工作正常后Keepalived自动将服务器加入到服务器群中,实现自动剔除与恢复,不需要人工干涉,需要人工做的只是修复故障的服务器。
Keepalived 健康检查可以在三层 - 五层之间:
三层机理是发送ICMP数据包即PING给某台服务器,如果不通,则认为其故障,并从服务器群中剔除;
四层机理是检测TCP端口号状态来判断某台服务器是否故障,如果检测端口存在异常,则从服务器群中剔除;
五层机理是根据用户的设定检查某个服务器应用程序是否正常运行,如果不正常,则从服务器群中剔除,比如说某个网页,可以通过http 状态码来判定是否正常。
详解 虚拟路由冗余协议(VRRP)协议 VRRP解决什么问题 VRRP 是 Virtual Router Redundancy Protocol 的简称,即 虚拟路由冗余协议 。
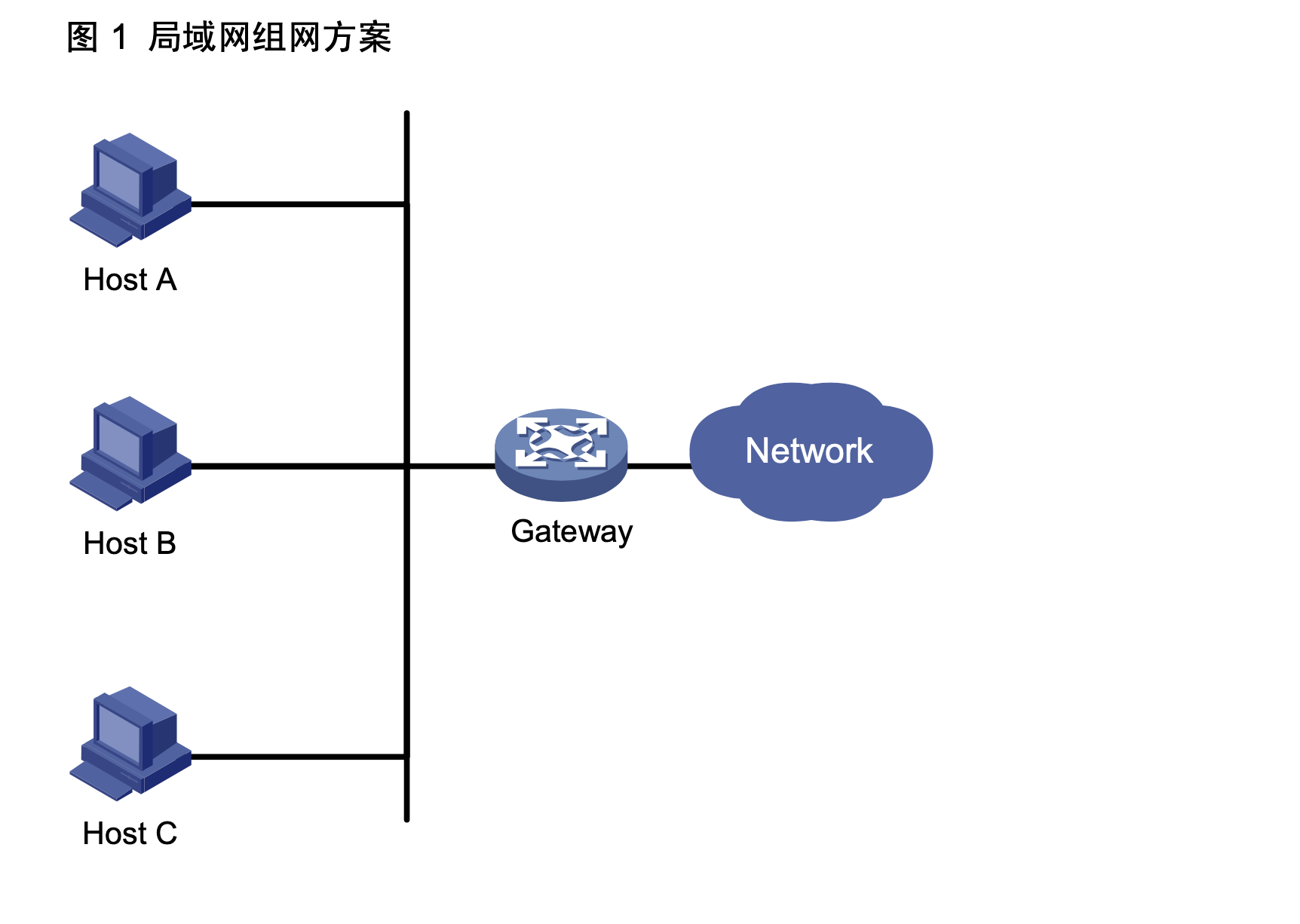
如图所示,通常,同一网段内的所有主机都设置一条相同的、以网关为下一跳的缺省路由。主机 发往其他网段的报文将通过缺省路由发往网关,再由网关进行转发,从而实现主机与外部网络的通信。
当网关发生故障时,本网段内所有以网关为缺省路由的主机将无法与外部网络通信。
所以,网关设备提出了很高的稳定性要求。增加出口网关是提高系统可靠性的常见方法,此时如何在多个出口之间进行选路就成为需要解决的问题。
VRRP,就是解决这个问题而存在的,它将可以承担网关功能的一组 路由器加入到备份组中,形成一台虚拟路由器,由 VRRP 的选举机制决定哪台路由器承担转发任务, 局域网内的主机只需将虚拟路由器配置为缺省网关。通俗的来讲就是将网关做成主备方案,用于容错。
VRRP 协议的实现有 VRRPv2 和 VRRPv3 两个版本。其中,VRRPv2 基于 IPv4,VRRPv3 基于 IPv6。 VRRPv2 和 VRRPv3 在功能实现上并没有区别,只是应用的网络环境不同。
VRRP 备份组 VRRP 将局域网内的一组路由器划分在一起,称为一个备份组。备份组由一个 Master 路由器和多个 Backup 路由器组成,功能上相当于一台虚拟路由器。 VRRP 备份组具有以下特点:
虚拟路由器具有IP地址,称为虚拟IP地址。局域网内的主机仅需要知道这个虚拟路由器的IP地址,并将其设置为缺省路由的下一跳地址。
网络内的主机通过这个虚拟路由器与外部网络进行通信。
备份组内的路由器根据优先级,选举出 Master 路由器,承担网关功能。其他路由器作为 Backup 路由器,当 Master 路由器发生故障时,取代 Master 继续履行网关职责,从而保证网络内的 主机不间断地与外部网络进行通信。
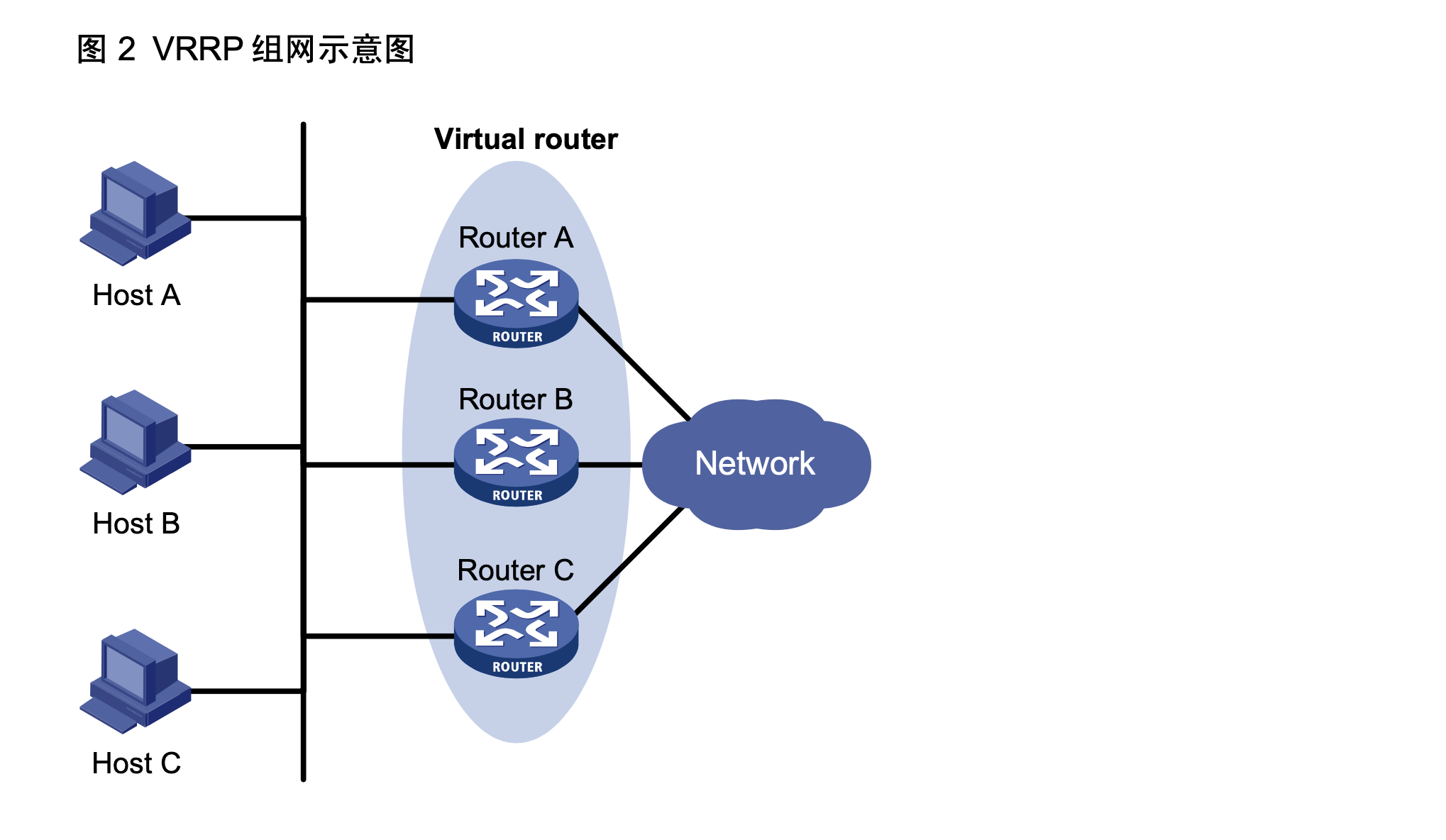
如 图 2所示,Router A、Router B和Router C组成一个虚拟路由器。此虚拟路由器有自己的IP地址。 局域网内的主机将虚拟路由器设置为缺省网关。Router A、Router B和Router C中优先级最高的路 由器作为Master路由器,承担网关的功能。其余两台路由器作为Backup路由器。
备份组相关概念
虚拟IP技术。虚拟IP,就是一个未分配给真实主机的IP,也就是说对外提供数据库服务器的主机除了有一个真实IP外还有一个虚IP,使用这两个IP中的任意一个都可以连接到这台主机
其实现原理主要是靠 TCP/IP 的 ARP 协议。因为IP地址只是一个逻辑地址,在以太网中 MAC 地址才是真正用来进行数据传输的物理地址,每台主机中都有一个 ARP 高速缓存,存储同一个网络内的 IP 地址与 MAC 地址的对应关系,以太网中的主机发送数据时会先从这个缓存中查询目标 IP 对应的 MAC 地址,会向这个 MAC 地址发送数据。操作系统会自动维护这个缓存。
一个虚拟路由器拥有一个虚拟MAC地址。虚拟MAC地址的格式为00-00-5E-00-01-{VRID}。通常情况下,虚拟路由器回应ARP请求使用的是虚拟MAC地址,只有虚拟路由器做特殊配置的时候,才回应接口的真实MAC地址。
角色
Master: 对外提供服务的主服务器,只能有一个
Backup: 备选防范,当Master 出现问题之后会取代master提供服务,可以有多个。
优先级
VRRP 根据优先级来确定备份组中每台路由器的角色(Master 路由器或 Backup 路由器)。优先级越高,则越有可能成为 Master 路由器。
VRRP 优先级的取值范围为 0 到 255(数值越大表明优先级越高),可配置的范围是 1 到 254,优 先级 0 为系统保留给特殊用途来使用,255 则是系统保留给 IP 地址拥有者。当路由器为 IP 地址拥 有者时,其优先级始终为 255。因此,当备份组内存在 IP 地址拥有者时,只要其工作正常,则为 Master 路由器。
工作方式
非抢占方式:如果备份组中的路由器工作在非抢占方式下,则只要 Master 路由器没有出现故 障,Backup 路由器即使随后被配置了更高的优先级也不会成为 Master 路由器。
抢占方式:如果备份组中的路由器工作在抢占方式下,它一旦发现自己的优先级比当前的 Master 路由器的优先级高,就会对外发送 VRRP 通告报文。导致备份组内路由器重新选举 Master 路由器,并最终取代原有的 Master 路由器。相应地,原来的 Master 路由器将会变成 Backup 路由器。
认证方式
simple:简单字符认证。发送 VRRP 报文的路由器将认证字填入到 VRRP 报文中,而收到 VRRP 报文的路由器会将收到的 VRRP 报文中的认证字和本地配置的认证字进行比较。如果 认证字相同,则认为接收到的报文是真实、合法的 VRRP 报文;否则认为接收到的报文是一 个非法报文。
md5:MD5 认证。发送 VRRP 报文的路由器利用认证字和 MD5 算法对 VRRP 报文进行摘要 运算,运算结果保存在Authentication Header(认证头)中。收到VRRP报文的路由器会利 用认证字和 MD5 算法进行同样的运算,并将运算结果与认证头的内容进行比较。如果相同, 则认为接收到的报文是真实、合法的 VRRP 报文;否则认为接收到的报文是一个非法报文。
定时器
VRRP 通告报文间隔时间定时器和
VRRP 备份组中的 Master 路由器会定时发送 VRRP 通告报文,通知备份组内的路由器自己工作正常。用户可以通过设置 VRRP 定时器来调整 Master 路由器发送 VRRP 通告报文的时间间隔。如果 Backup 路由器在等待了 3 个间隔时间后,依然没有收到 VRRP 通告报文,则认为自己是 Master 路由器,并对外发送 VRRP 通告报文,重新进行 Master 路由器的选举。
VRRP 抢占延迟时间定时器。
为了避免备份组内的成员频繁进行主备状态转换,让 Backup 路由器有足够的时间搜集必要的信息 (如路由信息),Backup 路由器接收到优先级低于本地优先级的通告报文后,不会立即抢占成为 Master,而是等待一定时间——抢占延迟时间后,才会对外发送 VRRP 通告报文取代原来的 Master 路由器。
VRRP 工作方式
选举MASTER:路由器使能 VRRP 功能后,会根据优先级确定自己在备份组中的角色。优先级高的路由器成 为 Master 路由器,优先级低的成为 Backup 路由器。Master 路由器定期发送 VRRP 通告报文, 通知备份组内的其他路由器自己工作正常;Backup 路由器则启动定时器等待通告报文的到来。
MASTER 通过ARP 协议对外通告该备份组的虚拟ip以及MAC地址
在抢占方式下,当 Backup 路由器收到 VRRP 通告报文后,会将自己的优先级与通告报文中 的优先级进行比较。如果大于通告报文中的优先级,则成为 Master 路由器;否则将保持 Backup 状态。
如果 Backup 路由器的定时器超时后仍未收到 Master 路由器发送来的 VRRP 通告报文,则认 为 Master 路由器已经无法正常工作,此时 Backup 路由器会认为自己是 Master 路由器,并对 外发送 VRRP 通告报文。备份组内的路由器根据优先级选举出 Master 路由器,承担报文的转 发功能。
Backup 通过ARP 协议对外通告该备份组的虚拟ip以及MAC地址
MASER 恢复之后,根据是否是抢占模式,逐步恢复对路由转发的功能。
Keepalived 配置详解 安装keepalived 1 yum install keepalived -y
配置文件详解
文件
说明
/usr/sbin/keepalived
二进制程序
/etc/keepalived/keepalived.conf
配置文件
/usr/lib/systemd/system/keepalived.service
服务文件
里面主要包括以下几个配置区域,分别是:
global_defs: 主要是配置故障发生时的通知对象以及机器标识。
static_ipaddress
static_routes
vrrp_script
vrrp_instance
virtual_server
global_defs区域
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 global_defs { notification_email { acassen@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc smtp_server 192.168.200.1 smtp_connect_timeout 30 router_id LVS_DEVEL vrrp_mcast_group4 224.0.0.18 vrrp_mcast_group6 ff02::12 }
static_ipaddress和static_routes区域[可忽略]
static_ipaddress和static_routes区域配置的是是本节点的IP和路由信息。如果你的机器上已经配置了IP和路由,那么这两个区域可以不用配置。其实,一般情况下你的机器都会有IP地址和路由信息的,因此没必要再在这两个区域配置。
1 2 3 4 5 6 7 8 static_ipaddress { 10.210.214.163/24 brd 10.210.214.255 dev eth0 ... } static_routes { 10.0.0.0/8 via 10.210.214.1 dev eth0 ... }
vrrp_script区域
用来做健康检查的,当时检查失败时会将vrrp_instance的priority减少相应的值。
1 2 3 4 5 6 vrrp_script chk_http_port { script "</dev/tcp/127.0.0.1/80" interval 1 weight -10 }
vrrp_instance和vrrp_sync_group区域
vrrp_instance用来定义对外提供服务的VIP区域及其相关属性。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 vrrp_sync_group VG_1 { group { inside_network outside_network ... } notify_master /path/to_master.sh notify_backup /path/to_backup.sh notify_fault "/path/fault.sh VG_1" notify /path/notify.sh smtp_alert } vrrp_instance VI_1 { state MASTER interface eth0 use_vmac dont_track_primary track_interface { eth0 eth1 } mcast_src_ip lvs_sync_daemon_interface eth1 garp_master_delay 10 virtual_router_id 1 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 12345678 } virtual_ipaddress { 192.168.200.16/24 dev eth1 192.168.200.17/24 dev label eth1:1 } virtual_routes { 172.16.0.0/12 via 10.210.214.1 192.168.1.0/24 via 192.168.1.1 dev eth1 default via 202.102.152.1 } track_script { chk_http_port } nopreempt preempt_delay 300 debug notify_master| notify_backup| notify_fault| notify| smtp_alert notify_master "" notify_backup "" notify_fault "" }
virtual_server_group和virtual_server区域1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 virtual_server IP Port { delay_loop lb_algo rr|wrr|lc|wlc|lblc|sh|dh lb_kind NAT|DR|TUN persistence_timeout persistence_granularity protocol TCP ha_suspend virtualhost alpha omega quorum hysteresis quorum_up| quorum_down| sorry_server real_server 192.168.200.2 1358 { weight 1 MISC_CHECK {} SMTP_CHEKC {} TCP_CHECK { connect_port <PORT> bindto <IP> connect_timeout 3 } SSL_GET {} notify_up "这里写的是路径,如果脚本后有参数,整体路径+参数引起来" notify_down "/PATH/SCRIPTS.sh 参数" HTTP_GET { url { path /testurl/test.jsp digest 640205b7b0fc66c1ea91c463fac6334d status_code 200 } url { path /testurl2/test.jsp digest 640205b7b0fc66c1ea91c463fac6334d } url { path /testurl3/test.jsp digest 640205b7b0fc66c1ea91c463fac6334d } connect_port <PORT> bindto <IP> connect_timeout 3 nb_get_retry 3 delay_before_retry 3 } }
1 2 3 4 5 6 [root@lvs-node-0 ~]# man 5 keepalived.conf [root@lvs-node-0 ~]# cd /etc/keepalived/ [root@lvs-node-0 keepalived]# ls keepalived.conf [root@lvs-node-0 keepalived]# cp keepalived.conf keepalived.conf.bak [root@lvs-node-0 keepalived]#
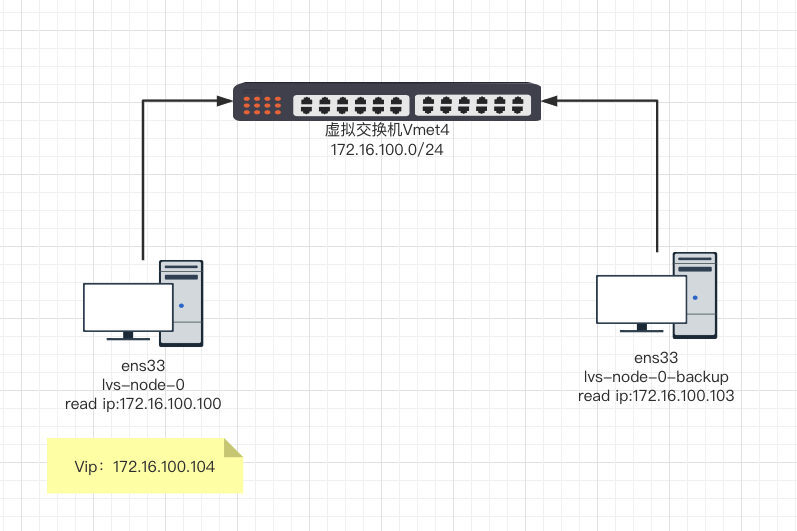
配置VIP漂移配置 本次来配置 vip 漂移配置 网络拓扑如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 global_defs { notification_email { root@localhost } notification_email_from roor@localhost smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id LVS_DEVEL } vrrp_instance VI_1 { state MASTER interface ens33 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 172.16.100.104/24 dev ens33 label ens33:1 } } global_defs { notification_email { root@localhost } notification_email_from roor@localhost smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id LVS_DEVEL } vrrp_instance VI_1 { state BACKUP interface ens33 virtual_router_id 51 priority 99 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 172.16.100.104/24 dev ens33 label ens33:1 } }
1 2 3 4 5 6 7 8 9 10 11 12 [root@lvs-node-0 keepalived]# systemctl restart keepalived [root@lvs-node-0 keepalived]# systemctl status keepalived ● keepalived.service - LVS and VRRP High Availability Monitor Loaded: loaded (/usr/lib/systemd/system/keepalived.service; disabled; vendor preset: disabled) Active: active (running) since 三 2021-05-12 11:38:41 CST; 16min ago Process: 6306 ExecStart=/usr/sbin/keepalived $KEEPALIVED_OPTIONS (code=exited, status=0/SUCCESS) Main PID: 6307 (keepalived) CGroup: /system.slice/keepalived.service ├─6307 /usr/sbin/keepalived -D ├─6308 /usr/sbin/keepalived -D └─6309 /usr/sbin/keepalived -D
我们可以通过日志看到 keepalived 一共启动了三个进程,分别是
1 2 3 ├─6307 /usr/sbin/keepalived -D ├─6308 /usr/sbin/keepalived -D └─6309 /usr/sbin/keepalived -D
keepalived正常启动的时候,共启动3个进程:
一个是父进程,负责监控其子进程;一个是VRRP子进程,另外一个是checkers子进程;
两个子进程都被系统watchlog(为keepalived程序当中的模块)看管,两个子进程各自负责复杂自己的事。
Healthcheck(为keepalived程序当中的模块)子进程检查各自服务器的健康状况,,例如http,lvs。如果healthchecks进程检查到master上服务不可用了,就会通知本机上的VRRP子进程,让他删除通告,并且去掉虚拟IP,转换为BACKUP状态。
查看配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 [root@lvs-node-0 keepalived]# ifconfig ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 172.16.100.100 netmask 255.255.255.0 broadcast 172.16.100.255 inet6 fe80::20c:29ff:fe15:e448 prefixlen 64 scopeid 0x20<link > ether 00:0c:29:15:e4:48 txqueuelen 1000 (Ethernet) RX packets 16648 bytes 11694770 (11.1 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 10336 bytes 1105559 (1.0 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ens33:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 172.16.100.104 netmask 255.255.255.0 broadcast 0.0.0.0 ether 00:0c:29:15:e4:48 txqueuelen 1000 (Ethernet) lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 1000 (Local Loopback) RX packets 56 bytes 5592 (5.4 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 56 bytes 5592 (5.4 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 [root@lvs-node-0-backup keepalived]# ifconfig ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 172.16.100.103 netmask 255.255.255.0 broadcast 172.16.100.255 inet6 fe80::fe47:7422:c78:9b51 prefixlen 64 scopeid 0x20<link > ether 00:0c:29:53:4c:39 txqueuelen 1000 (Ethernet) RX packets 11694 bytes 11187317 (10.6 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 5520 bytes 538341 (525.7 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 1000 (Local Loopback) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
下面我们做一下验证,将lvs-node-0 ens33网卡down 掉
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 [root@lvs-node-0 keepalived]# ifconfig ens33 down [root@lvs-node-0-backup keepalived]# ifconfig ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 172.16.100.103 netmask 255.255.255.0 broadcast 172.16.100.255 inet6 fe80::fe47:7422:c78:9b51 prefixlen 64 scopeid 0x20<link > ether 00:0c:29:53:4c:39 txqueuelen 1000 (Ethernet) RX packets 48331 bytes 13390569 (12.7 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 5572 bytes 544595 (531.8 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ens33:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 172.16.100.104 netmask 255.255.255.0 broadcast 0.0.0.0 ether 00:0c:29:53:4c:39 txqueuelen 1000 (Ethernet) lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 1000 (Local Loopback) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
Keepalived 手动宕机脚本 keepalived 支持 vrrp_script 配置,用于可以手动关闭 keepalived,用户手动切换vrrp 具体配置如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 vrrp_script chk_mt { script "/etc/keepalived/down.sh" interval 1 weight -20 } vrrp_instance VI_1 { track_script { chk_mt } }
/etc/keepalived/down.sh 内容如下(注意增加chmod +x down.sh) 权限
1 2 3 4 #!/bin/bash if [ -f /etc/keepalived/down ];then weight -2 fi
上面的配置为,当我们 /etc/keepalived/down 文件存在的时候,会将改keepalived 监控的vip 转移到 backup 机器上,笔者已经试验过,没有问题。
配置虚拟vip 变更之后的通知 本次主要配置当vip切换之后,需要给我们发邮件通知
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 通知脚本: vip=172.16.100.104 contact='root@localhost' notify mailsubject="`hostname` to be $1 : $vip floating" mailbody="`date '+%F %H:%M:%S'`: vrrp transition, `hostname` changed to be $1 " echo $mailbody | mail -s "$mailsubject " $contact } case "$1 " in master) notify master exit 0 ;; backup) notify backup exit 0 ;; fault) notify fault exit 0 ;; *) echo 'Usage: `basename $0` {master|backup|fault}' exit 1 ;; esac
再来看一下配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 vrrp_script chk_mt { script "/etc/keepalived/down.sh" interval 1 weight -20 } vrrp_instance VI_1 { track_script { chk_mt } notify_master "/etc/keepalived/notify.sh master" notify_backup "/etc/keepalived/notify.sh backup" notify_fault "/etc/keepalived/notify.sh fault" }
keepalived 配置 LVS DR 模型 关于LVS的细节,这里不再详细赘述,有兴趣的读者可以看负载均衡(3)LVS服务的搭建机及其高级应用
在准备两台服务器,lvs-node-1(172.16.100.101), lvs-node-2(172.16.100.101)
1 2 3 4 5 6 7 8 echo "1" >/proc/sys/net/ipv4/conf/all/arp_ignoreecho "1" >/proc/sys/net/ipv4/conf/lo/arp_ignoreecho "2" >/proc/sys/net/ipv4/conf/all/arp_announceecho "2" >/proc/sys/net/ipv4/conf/lo/arp_announceifconfig lo:0 172.16.100.104/32 broadcast 172.16.100.104 up route add -host 172.16.100.104 dev lo:0
在 lvs-node-0 和lvs-node-0-backup 编辑keepalived配置文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 vrrp_instance VI_1 { } virtual_server 172.16.100.104 80 { delay_loop 6 lb_algo wrr lb_kind DR nat_mask 255.255.244.0 protocol TCP real_server 172.16.100.101 80 { weight 1 HTTP_GET { url { path / status_code 200 } connect_timeout 3 nb_get_retry 3 delay_before_retry 3 } } real_server 172.16.100.102 80 { weight 2 HTTP_GET { url { path / status_code 200 } connect_timeout 3 nb_get_retry 3 delay_before_retry 3 } } }
在lvs-ndoe-0 上执行安装lvs 命令
1 2 3 ipvsadm -A -t 172.16.100.104:80 -s rr ipvsadm -a -t 172.16.100.104:80 -r 172.16.100.101:80 -g ipvsadm -a -t 172.16.100.104:80 -r 172.16.100.102:80 -g
在一台机器上执行是否生效:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ➜ ~ curl http://172.16.100.104 <!DOCTYPE html > <html > <head > </head > <body > <h1 > Welcome to nginx in lvs-node-2</h1 > </body > </html > ➜ ~ curl http://172.16.100.104 <!DOCTYPE html > <html > <head > </head > <body > <h1 > Welcome to nginx in lvs-node-1</h1 > </body > </html >
查看心跳信息:1 2 3 [root@lvs-node-2 ~]# tailf /var/log/nginx/access.log 172.16.100.100 - - [13/May/2021:15:04:02 +0800] "GET / HTTP/1.0" 200 101 "-" "KeepAliveClient" "-" 172.16.100.103 - - [13/May/2021:15:04:05 +0800] "GET / HTTP/1.0" 200 101 "-"
停掉一台lvs-node-2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 [root@lvs-node-2 ~]# systemctl stop nginx.service [root@lvs-node-2 ~]# [root@lvs-node-0 keepalived]# ipvsadm -L -n IP Virtual Server version 1.2.1 (size=4096) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 172.16.100.104:80 wrr -> 172.16.100.101:80 Route 1 0 0 [root@lvs-node-2 ~]# systemctl start nginx.service [root@lvs-node-0 keepalived]# ipvsadm -L -n IP Virtual Server version 1.2.1 (size=4096) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 172.16.100.104:80 wrr -> 172.16.100.101:80 Route 1 0 0 -> 172.16.100.102:80 Route 2 0 0 [root@lvs-node-0 keepalived]#
keepalived 双主模型搭建 以上的环境是基于主备模型,当master 节点工作正常的状态下,BACKUP是不对外提供服务的,这就意味着我们使用有一个节点处于备份状态,无法对外提供服务。这就会导致一部分的性能浪费,为了解决这个问题,提出了双主模型,也就是说 我们提供两个VIP 并且使用 DNS轮询的方式,使得两个keepalived 都在工作,互为准备,当一台机器失败之后,其中的vip 会转移到另外一个节点上去,该节点拥有两个vip 地址。
上面我们已经演示过如果搭建 LVS, 本次演示keepalived Track的功能,也就是监视功能。
keepalived 通过track 脚本实现对服务的监控, 根据服务的状态,改变路由器的优先级。当服务出现故障,被监视 Track 项的状态为 Negative,并将路由器的优先级降低指 定的数额。从而,使得备份组内其它路由器的优先级高于这个路由器的优先级,成为 Master 路由器,保证局域网内主机与外部网络的通信不会中断。
在 Backup 路由器上监视 Master 路由器的状态。当 Master 路由器出现故障时,工作在切换模 式的 Backup 路由器能够迅速成为 Master 路由器,以保证通信不会中断。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 vrrp_script chk_nginx { script "/etc/keepalived/chk_nginx.sh" interval 1 weight -20 } vrrp_instance VI_1 { state MASTER interface ens33 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } track_script { chk_nginx } virtual_ipaddress { 172.16.100.104/24 dev ens33 label ens33:1 } } vrrp_instance VI_2 { state BACKUP interface ens33 virtual_router_id 52 priority 99 advert_int 1 authentication { auth_type PASS auth_pass 2222 } track_script { chk_nginx } virtual_ipaddress { 172.16.100.105/24 dev ens33 label ens33:2 } }
lvs-node-0-backup keepalived 配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 vrrp_script chk_nginx { script "/etc/keepalived/chk_nginx.sh" interval 1 weight -20 } vrrp_instance VI_1 { state BACKUP interface ens33 virtual_router_id 51 priority 99 advert_int 1 authentication { auth_type PASS auth_pass 1111 } track_script { chk_nginx } virtual_ipaddress { 172.16.100.104/24 dev ens33 label ens33:1 } } vrrp_instance VI_2 { state MASTER interface ens33 virtual_router_id 52 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 2222 } track_script { chk_nginx } virtual_ipaddress { 172.16.100.105/24 dev ens33 label ens33:2 } }
/etc/keepalived/chk_nginx.sh 脚本
1 2 3 4 5 6 7 8 9 10 11 12 #!/bin/bash run=`ps -C nginx --no-header | wc -l` if [ $run -eq 0 ]then echo "stop nginx ....." systemctl stop nginx echo "start nginx ..." systemctl start nginx ps -C nginx --no-header sleep 3 fi
在lvs-node-0 和lvs-node-0-backup 上安装 nginx 配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 upstream monitor_server { server 172.16.100.102:80; server 172.16.100.101:80; } server { listen 80; server_name localhost; access_log /var/log/nginx/host.access.log main; location / { root /usr/share/nginx/html; index index.html index.htm; proxy_redirect off; proxy_set_header Host $host ; proxy_set_header X-Real-IP $remote_addr ; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for ; proxy_pass http://monitor_server; } }