Java对象内存布局
我们知道在Java中基本数据类型的大小,例如int类型占4个字节、long类型占8个字节,那么Integer对象和Long对象会占用多少内存呢?本文介绍一下Java对象在堆中的内存结构以及对象大小的计算。
对象的内存布局
一个Java对象在内存中包括对象头、实例数据和补齐填充3个部分:
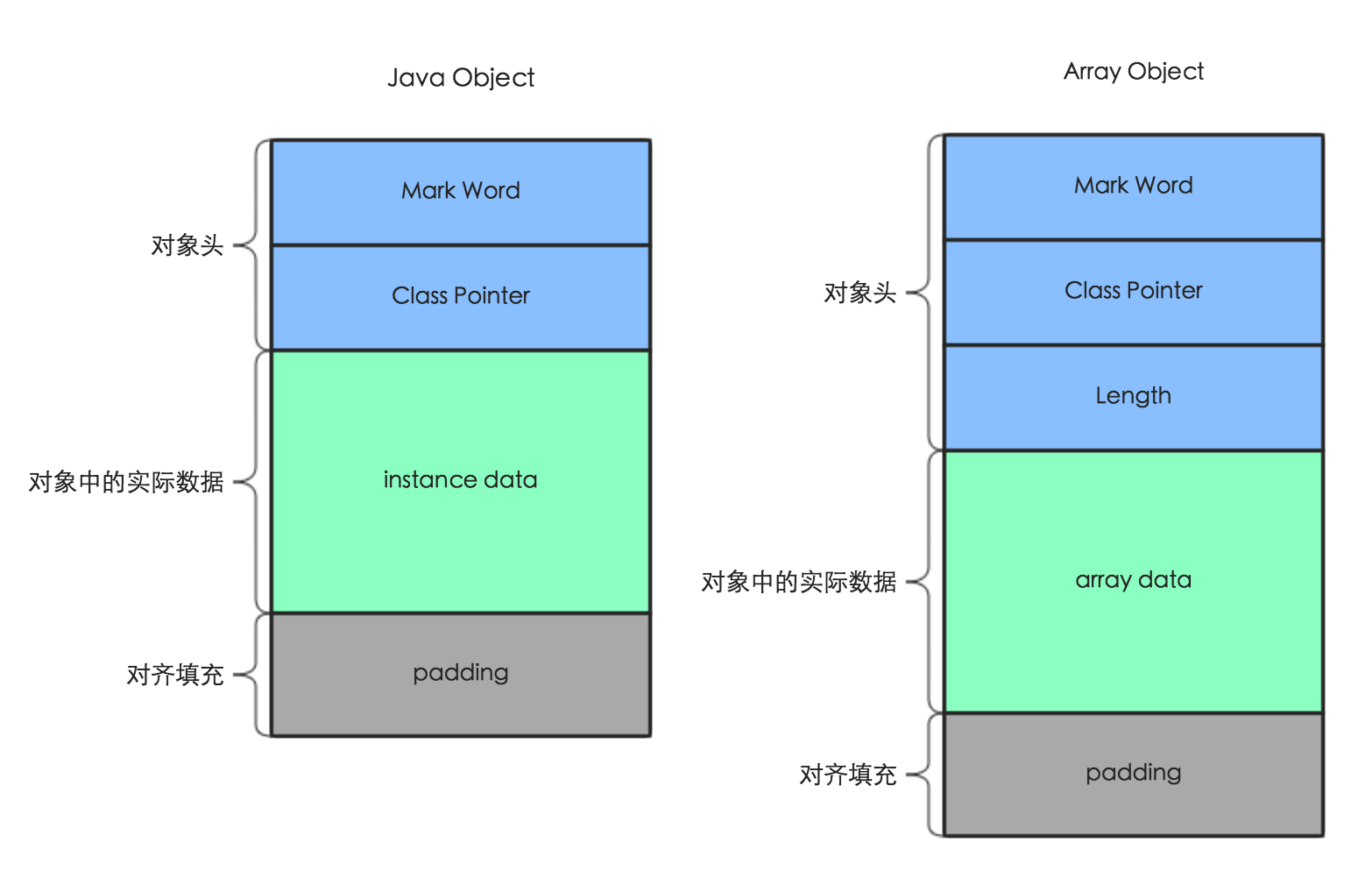
对象头
- Mark Word:包含一系列的标记位,比如轻量级锁的标记位,偏向锁标记位等等。在32位系统占4字节,在64位系统中占8字节;
- Class Pointer:用来指向对象对应的Class对象(其对应的元数据对象)的内存地址。在32位系统占4字节,在64位系统中占8字节;
- Length:如果是数组对象,还有一个保存数组长度的空间,占4个字节;
对象实际数据
对象实际数据包括了对象的所有成员变量,其大小由各个成员变量的大小决定,比如:byte和boolean是1个字节,short和char是2个字节,int和float是4个字节,long和double是8个字节,reference是4个字节(64位系统中是8个字节)。
| Primitive Type | Memory Required(bytes) |
|---|---|
| boolean | 1 |
| byte | 1 |
| short | 2 |
| char | 2 |
| int | 4 |
| float | 4 |
| long | 8 |
| double | 8 |
对于reference类型来说,在32位系统上占用4bytes, 在64位系统上占用8bytes。
对齐填充
Java对象占用空间是8字节对齐的,即所有Java对象占用bytes数必须是8的倍数。例如,一个包含两个属性的对象:int和byte,这个对象需要占用8+4+1=13个字节,这时就需要加上大小为3字节的padding进行8字节对齐,最终占用大小为16个字节。
注意:以上对64位操作系统的描述是未开启指针压缩的情况,关于指针压缩会在下文中介绍。
对象头分析
对象头占用空间大小
这里说明一下32位系统和64位系统中对象所占用内存空间的大小:
- 在32位系统下,存放Class Pointer的空间大小是4字节,MarkWord是4字节,对象头为8字节;
- 在64位系统下,存放Class Pointer的空间大小是8字节,MarkWord是8字节,对象头为16字节;
- 64位开启指针压缩的情况下,存放Class Pointer的空间大小是4字节,
MarkWord是8字节,对象头为12字节; - 如果是数组对象,对象头的大小为:数组对象头8字节+数组长度4字节+对齐4字节=16字节。其中对象引用占4字节(未开启指针压缩的64位为8字节),数组
MarkWord为4字节(64位未开启指针压缩的为8字节); - 静态属性不算在对象大小内。
对象头分析
HotSpot虚拟机的对象头(Object Header)包括两部分信息
-
第一部分用于存储对象自身的运行时数据, 如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等等,这部分数据的长度在32位和64位的虚拟机(暂不考虑开启压缩指针的场景)中分别为32个和64个Bits,官方称它为“Mark Word”。
-
对象需要存储的运行时数据很多,其实已经超出了32、64位Bitmap结构所能记录的限度,但是对象头信息是与对象自身定义的数据无关的额 外存储成本,考虑到虚拟机的空间效率,Mark Word被设计成一个非固定的数据结构以便在极小的空间内存储尽量多的信息,它会根据对象的状态复用自己的存储空间。
在 32 位系统下,存放 Class 指针的空间大小是 4 字节,Mark Word 空间大小也是4字节,因此头部就是 8 字节,如果是数组就需要再加 4 字节表示数组的长度,如下表所示:
在 64 位系统及 64 位 JVM 下,开启指针压缩,那么头部存放 Class 指针的空间大小还是4字节,而 Mark Word 区域会变大,变成 8 字节,也就是头部最少为 12 字节,如下表所示:

这里几个概念
- unused:未使用的
- epoch: 验证偏向锁有效性的时间戳
- cmd_free : cms垃圾收集器相关 可不用关心
关于偏向锁和重量解锁等相关的,这里不做讨论, 感兴趣的请参见我另外一篇博文深入分析synchronized原理和锁膨胀过程
直观的观察
我们使用JOL 工具来查看一下一个对象的真是内存布局。有关JOL的信息。
- 引入依赖
1 | <dependency> |
- 编写代码如下
1 | import org.openjdk.jol.info.ClassLayout; |
- 加入JVM参数
- -XX:-UseCompressedClassPointers
- -XX:-UseCompressedOops
这里是关闭类指针压缩和成员变量的指针压缩,关于指针压缩后面或详细分析,为了使得我们的实验不受到指针压缩的硬性,我们默认项关闭这两个指针压缩选项。
- 执行并得到输出如下
1 | java.lang.Object object internals: |
我们来分析一下
| OFFSET | SIZE | TYPE DESCRIPTION | VALUE |
|---|---|---|---|
| 0 | 4 | (object header) | 01 00 00 00 (00000001 00000000 00000000 00000000) (1) |
| 4 | 4 | (object header) | 00 00 00 00 (00000000 00000000 00000000 00000000) (0) |
| 8 | 4 | (object header) | 00 2c ad 0d (00000000 00101100 10101101 00001101) (229452800) |
| 12 | 4 | (object header) | 01 00 00 00 (00000001 00000000 00000000 00000000) (1) |
按照大小端重新排列一下得到:
由于我们是64位的系统,所以,我们的前8个字节位mark (64bit)结构如下
00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001
可以做如下划分:
| 0 - 55(56bit) | cms_free | 分带年龄 | 偏向锁 | 锁标志位 |
|---|---|---|---|---|
| 00000000 00000000 00000000 00000000 00000000 00000000 00000000 | 0 | 0000 | 0 | 01 |
后面8个字节如下(Class Pointer)表示对象的类的指针。
00001101 10101101 00101100 00000000 00000001 00000000 00000000 00000000
- 这里我们看到mark word 是无所状态,但是并没存贮hashcode。这是因为,如果我们要存入hashcode,必须要执行一次hascode代码,我们修改上述代码为
1 | private static void objectLayout() { |
输出如下:
1 | hash code:1581781576:1011110010010000001001001001000 |
我们依然按照上面的来划分得到:
| 0 - 23 | 24-55(56bit) hashcode | cms_free | 分带年龄 | 偏向锁 | 锁标志位 |
|---|---|---|---|---|---|
| 00000000 00000000 00000000 | 01011110 01001000 00010010 01001000 |
0 | 0000 | 0 | 01 |
而:hash code:1581781576:1011110010010000001001001001000
由此我们可以得到结论 在对象头的 24-55 位的bit 存放的是 hashcode值。
指针压缩
从上文的分析中可以看到,64位JVM消耗的内存会比32位的要多大约1.5倍,这是因为对象指针在64位JVM下有更宽的寻址。对于那些将要从32位平台移植到64位的应用来说,平白无辜多了1/2的内存占用,这是开发者不愿意看到的。
从JDK 1.6 update14开始,64位的JVM正式支持了 -XX:+UseCompressedOops 这个可以压缩指针,起到节约内存占用的新参数。
我们刚才在启动的虚拟机上增加了两个选项:
- UseCompressedOops:普通对象指针压缩
- UseCompressedClassPointers:类指针压缩
什么是OOP?
OOP的全称为:Ordinary Object Pointer,就是普通对象指针。启用CompressOops后,会压缩的对象:
- 每个Class的属性指针(静态成员变量);
- 每个对象的属性指针;
- 普通对象数组的每个元素指针。
当然,压缩也不是所有的指针都会压缩,对一些特殊类型的指针,JVM是不会优化的,例如指向PermGen的Class对象指针、本地变量、堆栈元素、入参、返回值和NULL指针不会被压缩。
启用指针压缩
在Java程序启动时增加JVM参数:-XX:+UseCompressedOops来启用。
注意:32位HotSpot VM是不支持UseCompressedOops参数的,只有64位HotSpot VM才支持。
本文中使用的是JDK 1.8,默认该参数就是开启的。
UseCompressedClassPointers 与 UseCompressedOops
由于UseCompressedClassPointers的开启是依赖于UseCompressedOops的开启。因此,要使UseCompressedClassPointers起作用,得先开启UseCompressedOops,并且开启UseCompressedOops 也默认开启UseCompressedClassPointers,关闭UseCompressedOops 默认关闭UseCompressedClassPointers。
如果开启了 UseCompressedClassPointers 但是关闭额 UseCompressedOops
1 | -XX:+UseCompressedClassPointers -XX:-UseCompressedOops |
观察开启指针压缩时的对象大小
增加 -XX:+UseCompressedClassPointers -XX:+UseCompressedOops
再次运行 objectLayout 方法
得到输出如下:
1 | java.lang.Object object internals: |
我们看到了有这么一句话 loss due to the next object alignment
表示的是 从12 开始 有4个B 用于对齐。所有开启针织压缩后 对于类指针由8个字节压缩到了4个字节。
其他方式查看对象大小
我们也可以使用http://www.javamex.com/中提供的classmexer.jar来计算对象的大小。 具体用法需加上-javaagent 参数
1 |
|
注意:在运行前需要设置javaagent参数,在JVM启动参数中添加-javaagent:/path_to_agent/classmexer.jar来运行。
有关Shallow Size和Retained Size请参考http://blog.csdn.net/e5945/article/details/7708253。
开启指针压缩的情况
运行查看结果:
1 | Shallow Size: 24 bytes |
根据上文的分析可以知道,64位开启指针压缩的情况下:
- 对象头大小=Class Pointer的空间大小为4字节+
MarkWord为8字节=12字节; - 实际数据大小=int类型4字节+long类型8字节=12字节(静态变量不在计算范围之内)
在MAT中分析的结果如下:
%5D(/2017/05/06/Java%E5%AF%B9%E8%B1%A1%E5%86%85%E5%AD%98%E5%B8%83%E5%B1%80/dump1.png)java-mem-objecat_.png)
所以大小是24字节。其实这里并没有padding,因为正好是24字节。如果我们把long b;换成int b;之后,再来看一下结果:
1 | Shallow Size: 24 bytes |
大小并没有变化,说明这里做了padding,并且padding的大小是4字节。
这里的Shallow Size和Retained Size是一样的,因为都是基本数据类型。
关闭指针压缩的情况
如果要关闭指针压缩,在JVM参数中添加-XX:-UseCompressedOops来关闭,再运行上述代码查看结果:
1 | Shallow Size: 24 bytes |
分析一下在64位未开启指针压缩的情况下:
- 对象头大小=Class Pointer的空间大小为8字节+
MarkWord为8字节=16字节; - 实际数据大小=int类型4字节+long类型8字节=12字节(静态变量不在计算范围之内);
这里计算后大小为16+12=28字节,这时候就需要padding来补齐了,所以padding为4字节,最后的大小就是32字节。
我们再把long b;换成int b;之后呢?通过上面的计算结果可以知道,实际数据大小就应该是int类型4字节+int类型4字节=8字节,对象头大小为16字节,那么不需要做padding,对象的大小为24字节:
1 | Shallow Size: 24 bytes |
数组类型
64位系统中,数组对象的对象头占用24 bytes,启用压缩后占用16字节。比普通对象占用内存多是因为需要额外的空间存储数组的长度。基础数据类型数组占用的空间包括数组对象头以及基础数据类型数据占用的内存空间。由于对象数组中存放的是对象的引用,所以数组对象的Shallow Size=数组对象头+length _引用指针大小,Retained Size=Shallow Size+length_每个元素的Retained Size。
代码如下:
1 |
|
开启指针压缩的情况
结果如下:
1 | Shallow Size: 16 bytes |
Shallow Size比较简单,这里对象头大小为12字节, 实际数据大小为4字节,所以Shallow Size为16。
对于Retained Size来说,要计算数组占用的大小,对于数组来说,它的对象头部多了一个用来存储数组长度的空间,该空间大小为4字节,所以数组对象的大小=引用对象头大小12字节+存储数组长度的空间大小4字节+数组的长度数组中对象的Retained Size+padding大小*
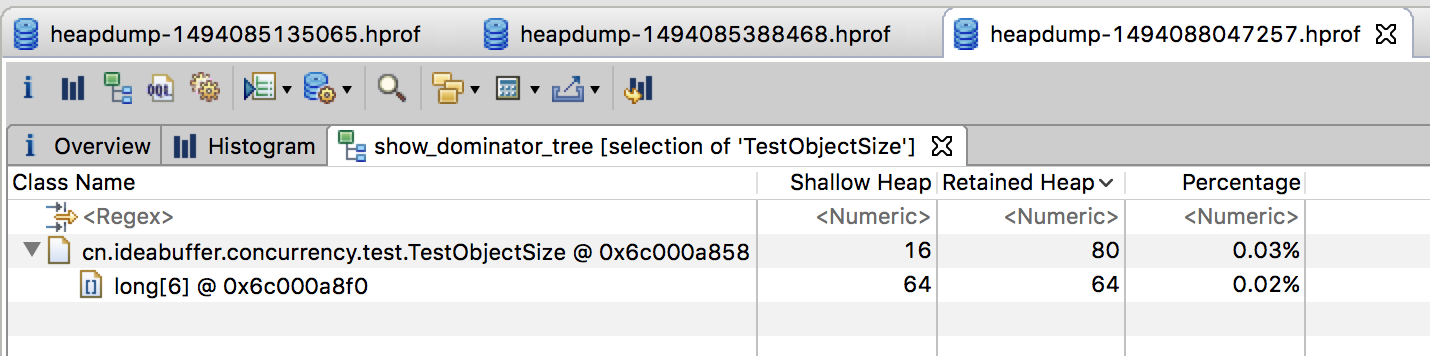
下面分析一下上述代码中的long[] arr = new long[6];,它是一个长度为6的long类型的数组,由于long类型的大小为8字节,所以数组中的实际数据是6*8=48字节,那么数组对象的大小=12+4+6*8+0=64,最终的Retained Size=Shallow Size + 数组对象大小=16+64=80。
通过MAT查看如下:
关闭指针压缩的情况
结果如下:
1 | Shallow Size: 24 bytes |
这个结果大家应该能自己分析出来了,因为这时引用对象头为16字节,那么数组的大小=16+4+6*8+4=72,(这里最后一个4是padding),所以Retained Size=Shallow Size + 数组对象大小=24+72=96。
通过MAT查看如下:

包装类型
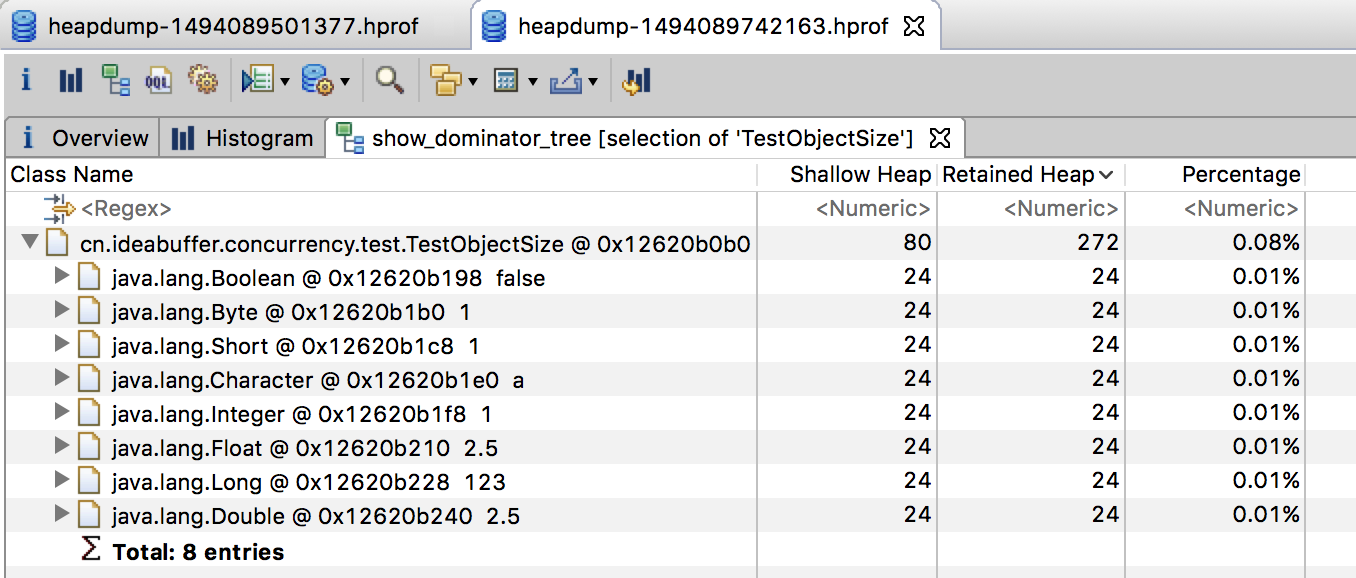
包装类(Boolean/Byte/Short/Character/Integer/Long/Double/Float)占用内存的大小等于对象头大小加上底层基础数据类型的大小。
包装类型的Retained Size占用情况如下:
| Numberic Wrappers | +useCompressedOops | -useCompressedOops |
|---|---|---|
| Byte, Boolean | 16 bytes | 24 bytes |
| Short, Character | 16 bytes | 24 bytes |
| Integer, Float | 16 bytes | 24 bytes |
| Long, Double | 24 bytes | 24 bytes |
1 | /** |
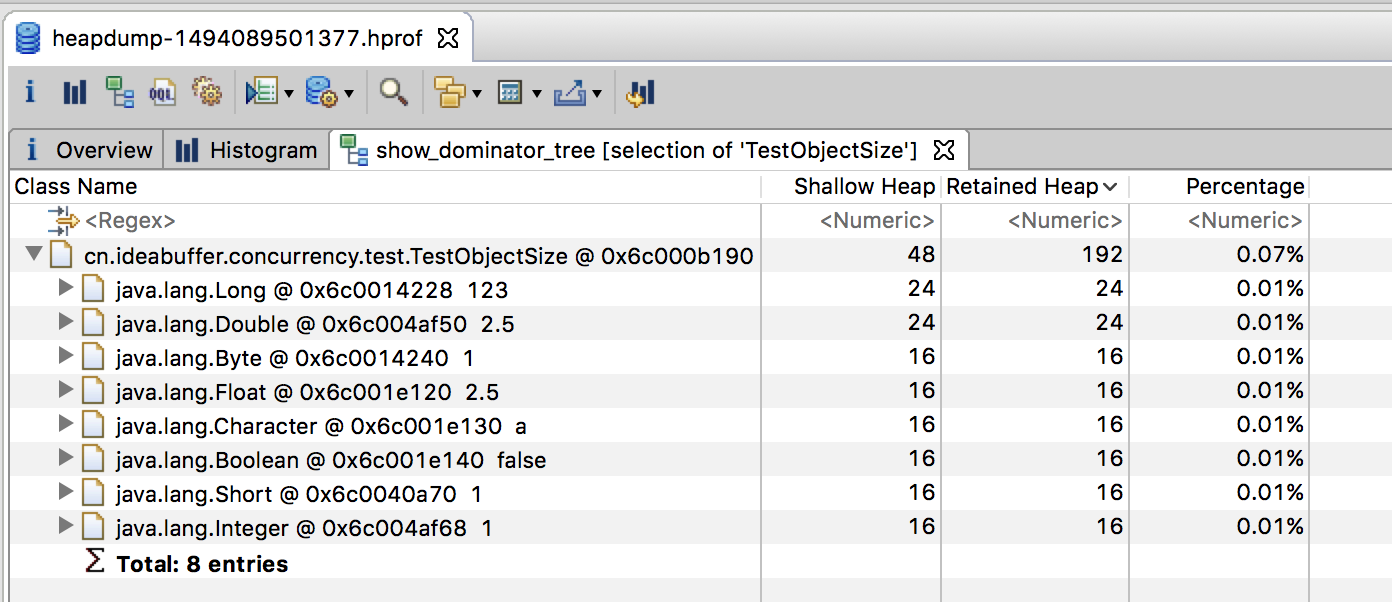
开启指针压缩的情况
结果如下:
1 | Shallow Size: 48 bytes |
MAT中的结果如下:
关闭指针压缩的情况
结果如下:
1 | Shallow Size: 80 bytes |
MAT中的结果如下:
String类型
在JDK1.7及以上版本中,java.lang.String中包含2个属性,一个用于存放字符串数据的char[], 一个int类型的hashcode, 部分源代码如下:
1 |
|
因此,在关闭指针压缩时,一个String对象的大小为:
-
Shallow Size=对象头大小16字节+int类型大小4字节+数组引用大小8字节+padding4字节=32字节;
-
Retained Size=Shallow Size+char数组的Retained Size。
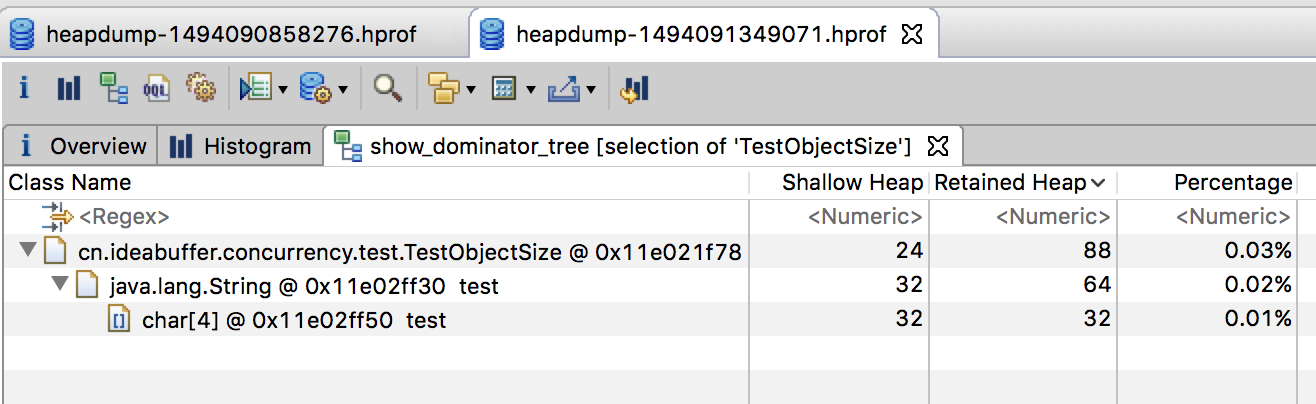
在开启指针压缩时,一个String对象的大小为:
-
Shallow Size=对象头大小12字节+int类型大小4字节+数组引用大小4字节+padding4字节=24字节;
-
Retained Size=Shallow Size+char数组的Retained Size。
代码如下:
1 |
|
开启指针压缩的情况
结果如下:
1 |
|
MAT中的结果如下:
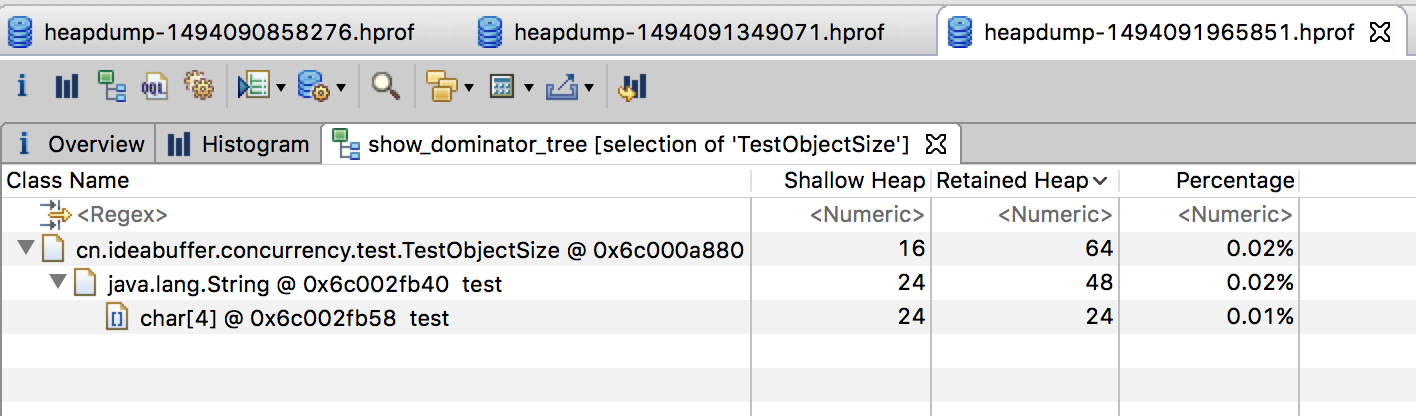
关闭指针压缩的情况
结果如下:
1 | Shallow Size: 24 bytes |
MAT中的结果如下:
其他引用类型的大小
根据上面的分析,可以计算出一个对象在内存中的占用空间大小情况,其他的引用类型可以参考分析计算过程来计算内存的占用情况。
关于padding
思考这样一个问题,是不是padding都加到对象的后面呢,如果对象头占12个字节,对象中只有1个long类型的变量,那么该long类型的变量的偏移起始地址是在12吗?用下面一段代码测试一下:
1 |
|
这里使用Unsafe类来查看变量的偏移地址,运行后结果如下:
1 | 1 |
如果是换成int类型的变量呢?结果是12。
现在一般的CPU一次直接操作的数据可以到64位,也就是8个字节,那么字长就是64,而long类型本身就是占64位,如果这时偏移地址是12,那么需要分两次读取该数据,而如果偏移地址从16开始只需要通过一次读取即可。int类型的数据占用4个字节,所以可以从12开始。
把上面的代码修改一下:
1 |
|
运行结果如下:
1 | 16 |
在本例中,如果变量的大小小于等于4个字节,那么在分配内存的时候会先优先分配,因为这样可以减少padding,比如这里的b和c变量;如果这时达到了16个字节,那么其他的变量按照类型所占内存的大小降序分配。
再次修改代码:
1 | /** |
结果如下:
1 | field a --> 40 |
可以看到,先分配的是int类型的变量e,因为它正好是4个字节,其余的都是先从g和h变量开始分配的,因为这两个变量是long类型和double类型的,占64位,最后分配的是a和b,它们只占一个字节。
如果分配到最后,这时字节数不是8的倍数,则需要padding。这里实际的大小是42字节,所以padding6字节,最终占用48字节。
原文地址
赞赏一下