前言
在我的Java内存模型(1)JMM是什么 中我已经阐述了JMM是什么以及CPU缓存模型和流水线的技术,下面针对于指令重排序中的编译器重排序做深入的讨论。
内存模型在JVM的应用
首先,我们再来重温一下,三种重排序。
重排序
指令重排序:在执行程序时为了提高性能,编译器和处理器常常会对指令做重排序。重排序分三种类型:
- 编译器优化的重排序
编译器在不改变单线程程序语义的前提下(代码中不包含synchronized关键字),可以重新安排语句的执行顺序。(就是本文要介绍的)
- 指令级并行的重排序
现代处理器采用了指令级并行技术(Instruction-Level Parallelism, ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。(具体细节可以参考Java内存模型(1)JMM是什么)
- 内存系统的重排序
由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。(原因请参参考CPU缓存一致性协议深入理解内存屏障)
从java源代码到最终实际执行的指令序列,会分别经历下面三种重排序
这里主要分享一下一下编译器优化重排序.
编译器重排序
什么是编译器重排序
编译器会对高级语言(本文里特指C/C++)的代码进行分析,当编译器认为你的代码可以优化的话,编译器会选择对代码进行优化然后生成汇编代码,当然编译器的优化满足特定的条件,这里要说一下大名鼎鼎的as-if规则:
Allows any and all code transformations that do not change the observable behavior of the program.
也就是说在不影响这段代码结果的前提下,编译器可以使用任意一种方式对代码进行编译,这也就给了编译器充分的空间对代码进行优化,从而提高代码的运行效率。
编译器重排序
举个例子,下面是一段简单的C语言代码:
环境如下:
1 | Linux CentOS7 3.10.0-1127.19.1.el7.x86_64 #1 SMP Tue Aug 25 17:23:54 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux |
我们编译的时候后使用 -O2 进行编译器优化。然后我们使用objdump进行反汇编代码的查看。编译器的优化选项的 4 个级别,-O0 表示没有优化, -O1 为默认值,-O3 优化级别最高。
1 | // foo.c |
当然,我们也可以使用线上的工具进行编译查看 https://godbolt.org/
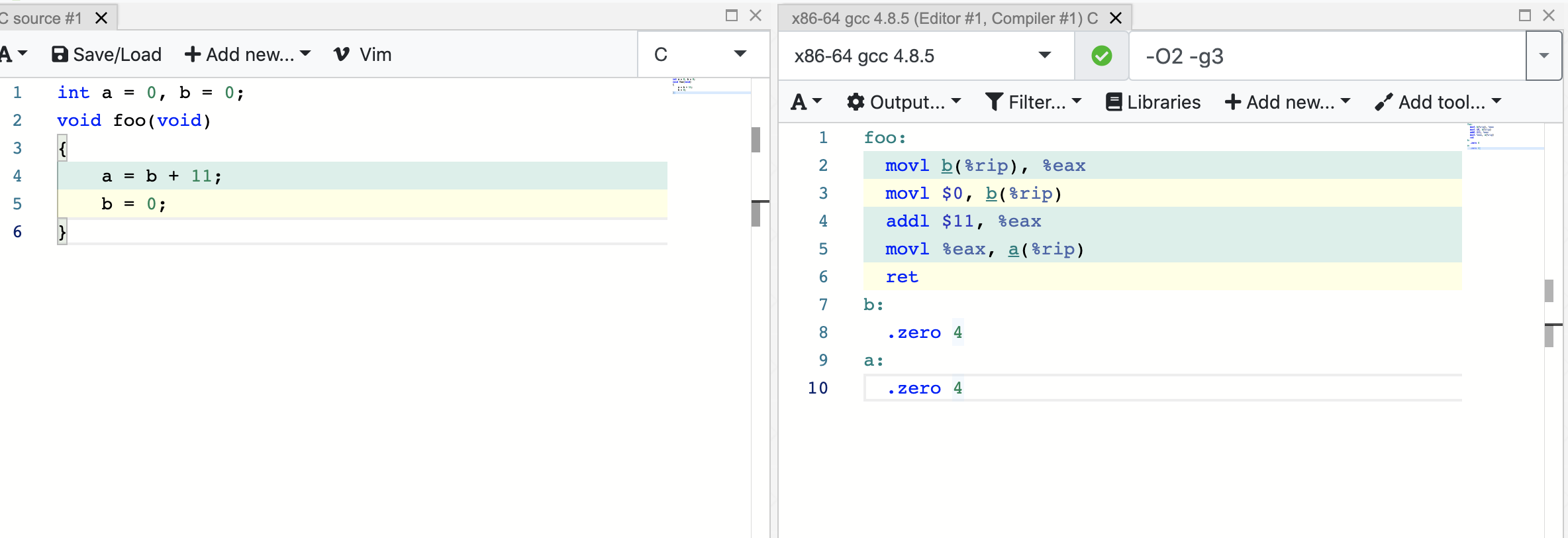
我们来解释一下代码:
| 编译结果 | 网站结果 | 含义 |
|---|---|---|
| mov 0x200b1a(%rip),%eax | movl b(%rip), %eax | 将rip寄存器里的地址中的值, 赋值给 eax寄存器 |
| movl $0x0,0x200b10(%rip) | movl $0, b(%rip) | 将 0 赋值到 rip寄存器里地址 |
| add $0xb,%eax | add $11, %eax | 将 11 + eax 寄存器里(上面说了是rip寄存器的值) |
| mov %eax,0x200b0b(%rip) | mov %eax, a(%rip) | 将集群器eax 里的值赋值给 rip里地址的区域 |
rip 寄存器涉及寻址,我们这里不做讨论,只要知道
- 1、首先,rip 里存放的是b的地址,b的地址里放着b的初始值
- 2、将b的地址的值赋值给了eax, 然后 将0复制给了rip里地址地址,也就是b, 然后将11 加上 eax 寄存器的值(我们知道,eax是b的初始值),最后,将结果给了rip的地址(此时rip已经执向a的地址)
我们发现,编译得到的汇编代码和我们原本的C语言代码不顺序并不一致,而是相当于如下C语言代码:
1 | int a, b; |
编译器的本意是提升程序在CPU上的运行性能,更好的使用寄存器以及现代处理器的流水线技术,减少汇编指令的数量,降低程序执行需要的CPU周期,减少CPU读写主存的时间,但是在多核多线程并行的情况下,这种重排序优化就有可能导致共享变量的可见性问题。
当然编译器的优化也不仅限于对于代码的重排序,编译器还会优化掉它认为不需要的一些变量,同时也会将一些本应去内存中取得数据存入寄存器中,然后下次取得时候就可以直接从寄存器中获取(这样也可能导致多线程中共享变量的可见性问题)。
当然,as-if规则在单核CPU时代是完全没有问题的,但是随着CPU的发展,出现了可以多核并行的CPU,这时编译器重排序就可能导致一些令人意想不到的问题,这点我们从感性认知上就可以理解,因为在多线程编程中经常会使用一些共享变量来实现不同线程的控制或者数据传输,但是如果编译器把我们精心设计的代码顺序进行了“优化“,就有可能出现我们不希望出现的运行结果
编译器优化
前面我一直想用“优化"这个词,而不是用”重排序”这个词,是因为编译器对于代码的优化不仅限于重排序,编译器同时会删除一些它认为无用的代码,更重要的是,会把一些变量放进寄存器中!
1 | int run = 1; |
首先来看一下 几个指令的含义
test a,b是做 AND 运算(虽然通常是用来测试结果是否为零,但不限于此,比如一些位掩码操作,或者正负号判断等),但不把结果写回目的操作数,仅根据结果的值来置标志位。
jne当运算结果不为0时则跳转
jmp为无条件跳转
- 从rip地址中取的run的值放入 eax寄存器
- 判断寄存器eax当中的值是不是0
- 如果不是0 则跳转到 40050c 这个地址
- 40050c 地址的指令为 jmp 40050c 无条件循环
那么问题来了,这里跳转以后并没有重新去取内存中run的值,而是进入了死循环,也就是说这段代码理论上会一直运行下去,即使别的线程会去更改内存中run的值,也不会跳出循环,其实这就导致了多线程中共享变量的可见性问题。
禁止重排序/优化
之前已经说了,多线程情况下编译器优化会导致一些问题的出现,那么有没有方法来阻止编译器的优化呢?答案是肯定的,而且方式还不止一种:
- 将变量声明为volatile变量(注意:Java中的volatile变量更强大)
- 代码中插入编译器屏障(Compiler Barrier),阻止编译器对屏障前后的代码进行优化,因此编译器屏障也被叫做优化屏障(Optimization Barrier)
为了防止读者误解,在这里先做说明:C/C++中将变量声明为volatile相当于对这个变量的每一次操作前后插入一个编译器屏障。了解了这一点前提后,我们就能更好的解释后续的一些概念。
编译器屏障的作用是什么?阻止编译器对屏障前后的代码进行重排序优化,同时阻止编译器将变量置入寄存器中随后直接使用,而是需要取内存中(或者CPU缓存中)的变量值进行运算操作。简而言之,就是禁止编译屏障前后编译器对于变量操作的优化(重排序、从寄存器中取值使用)
禁止重排序
我们来看源码,注意编译还是用的 以上 -O2的编译优化等级。
1 |
|
我们继续编译
1 | 0000000000400510 <foo>: |
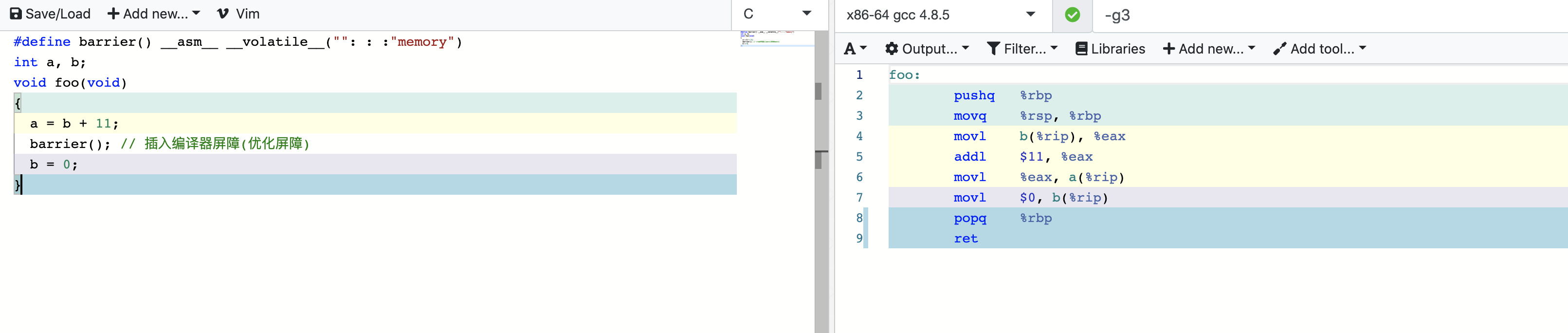
再来根据上面的方法进行分析,我们得到了 b = 0 已经确实移动到了 a = b + 1 之后了。 原因在于我们加了一个屏障。
1 |
这是是一段内嵌汇编代码, __asm__代表C语言内嵌汇编代码,__volatile__ 是告诉编译器不要把这行代码进行任何优化
(“”: : :”memory”)这个比较复杂,但是在这里只需要知道,这段代码的意思是告诉编译器“内存发生了改变”,因此GCC编译时就会知道,不能使用寄存器中的值,而是要去内存中取值,且不能将屏障前后的代码重排序。
可以看到,使用了编译器屏障以后,代码并没有进行重排序,之前也提到编译器还会对代码进行优化,将本来应该从内存中取值的变量放在寄存器中,那么编译器屏障能解决这个现象吗?
内存取值
本文之前提到,编译器会将变量放入CPU寄存器中,减少访问内存(缓存)耗时,但是有些情况下放入寄存器会导致多线程环境下的变量不可见性。
那么编译器屏障能解决这个问题吗?我们看之前的代码插入编译器屏障以后:
1 |
|
编译得到
1 | 0000000000400500 <foo>: |
编译后,我们可以看到 jne 直接跳到了 400508 而 400508段指令为:mov 0x200b1e(%rip),%eax,
表示 run 从地址中取值,而不是直接死循环了。相较于之前的跳转到本行的行为,相当于消除了编译器对于变量存入寄存器的优化。
volatile(C/C++)
相应的,也可以通过把run变量声明为volatile变量,告诉编译器这个变量的不可优化。
1 | int volatile run; |
1 | 0000000000400500 <foo>: |
可以看到 jne 跳到了400500 行,而 400500 行正式从内存中取值run
C/C++中的volatile关键字作用和Java中是不同的,Java中volatile关键字相当于C/C++的加强版,至于怎么进行加强,以后我会着重说一说。
C/C++中的volatile关键字,我之说过,相当于对这个变量前后插入了内存屏障,其实这样说有些不够精确,其核心作用就是禁止编译器对于这个变量/代码块进行任何优化,禁止重排序、禁止使用寄存器而不取内存值、禁止编译器将其认为无用的代码优化掉。
但是Linux内核编程中是很抵制程序员使用volatile关键字的,因为Linux本身对于同步控制提供了各种API,都可以替代直接使用volatile关键字,其实Linux和JVM设计思路上有些一直,屏蔽了这些API的实现细节,就像JVM屏蔽了volatile、synchronized关键字的实现细节。但是有一点不得不说,无论是Linux还是JVM,底层都使用到了编译器屏障来防止一些问题的出现。
其他方式禁止实现编译器屏障
试想一下,除了__asm__ __volatile__("": : :"memory") 和 c++ 的volatile 关键字之外,还有什么方法可以实现编译器屏障的效果呢?我在openjdk1.8 的hotspot的时候见到过这样实现屏障的
1 | //将寄存器栈顶值复制给局部变量,保证了编译器不会重排序 |
可以看到,这里是将 将寄存器栈顶值复制给局部变量。这个局部变量又是 volatile 的。不难看出,如果 barrier 换成了 __asm__ volatile ("movq 0(%%rsp), %0" : "=r" (local_dummy) : : "memory") 之后, 其实和__asm__ __volatile__("": : :"memory") 实现的效果差不多,只不过多了一步将寄存器栈顶值复制给局部变量, 后续就会释放这个局部局部变量,他的根本目的还是在于将barrier 前后的代码分割开来,破坏优化形成的条件。
但是jdk9以后统一使用了__asm__ __volatile__("": : :"memory") 这种写法,看来这种写法冗余了,但是当初为什么这么写我没有找到资料,这里存个疑。但是有一种说法是为了让该变量独立落在一个缓存行当中,所以在这里定义了一个内部无用的变量。
下一篇,我会讨论Java volatile 和 synchronized 关键字的底层实现原理。
结束
之所以介绍编译器屏障,是因为在jvm当中曾经大量使用了屏障,编译解析阶段,都存在屏障的代码,后续的文章中,我会逐一介绍。
参考
赞赏一下