内存模型
内存模型的分类
内存一致性模型(memory consistency model)就是用来描述多线程对共享存储器的访问行为,在不同的内存一致性模型里,多线程对共享存储器的访问行为有非常大的差别。这些差别会严重影响程序的执行逻辑,甚至会造成软件逻辑问题。在后面的介绍中,我们将分析不同的一致性模型里,多线程的内存访问乱序问题。
在分析之前,我们先定义一个基本的内存模型,以这个内存模型为基础进行分析:
1 |
|
上图是现代CPU的基本内存模型,CPU内部有多级缓存来提高CPU的load/store访问速度(因为对于CPU而言,主存的访问速度太慢了,上百个时钟周期的内存访问延迟会极大的降低CPU的使用效率,所以CPU内部往往使用多级缓存来提升内存访问效率。)
C1与C2是CPU的2个核心,这两个核心有私有缓存L1,以及共享缓存L2。最后一级存储器才是主存。后面的顺序一致性模型(SC)中,我们会以这个为基础进行描述(在完全存储定序、部分存储定序和宽松内存模型里会有所区别,后面会描述相关的部分)
了简化描述的复杂性,在下面的内存一致性模型描述里,会先将缓存一致性(cache coherence)简单化,认为缓存一致性是完美的(假设多核cache间的数据同步与单核cache一样,没有cache引起的数据一致性问题),以减少描述的复杂性。
目前有多种内存一致性模型:
顺序存储模型(sequential consistency model)(SC模型)
顺序存储模型是最简单的存储模型,也称为强定序模型。CPU会按照代码来执行所有的load与store动作,即按照它们在程序的顺序流中出现的次序来执行。从主存储器和CPU的角度来看,load和store是顺序地对主存储器进行访问。
完全存储定序(total store order)(TSO模型)
为了提高CPU的性能,芯片设计人员在CPU中包含了一个存储缓存区(store buffer),它的作用是为store指令提供缓冲,使得CPU不用等待存储器的响应。
首先我们需要对上面的基础内存模型做一些修改,表示这种新的内存模型
1 |
|
相比于以前的内存模型而言,store的时候数据会先被放到store buffer里面,然后再被写到L1 cache里。
首先我们思考单核上的两条指令:
1 | S1:store flag= set |
如果在顺序存储模型中,S1肯定会比S2先执行。但是如果在加入了store buffer之后,S1将指令放到了store buffer后会立刻返回,这个时候会立刻执行S2。
S2是read指令,CPU必须等到数据读取到r1后才会继续执行。这样很可能S1的store flag=set指令还在store buffer上,而S2的load指令可能已经执行完(特别是data在cache上存在,而flag没在cache中的时候。这个时候CPU往往会先执行S2,这样可以减少等待时间)
这里就可以看出再加入了store buffer之后,内存一致性模型就发生了改变。
如果我们定义store buffer必须严格按照FIFO的次序将数据发送到主存(所谓的FIFO表示先进入store buffer的指令数据必须先于后面的指令数据写到存储器中),这样S3必须要在S1之后执行,CPU能够保证store指令的存储顺序,这种内存模型就叫做完全存储定序(TSO)。
在store buffer被引入之后,内存一致性模型已经发生了变化(从SC模型变为了TSO模型),会出现store-load乱序的情况,这就造成了代码执行逻辑与我们预先设想不相同的情况。
在我的上一篇博文CPU缓存一致性协议 有详细的说明引入 store buffer 之后所带来的影响
部分存储定序(part store order)(PSO模型)
芯片设计人员并不满足TSO带来的性能提升,于是他们在TSO模型的基础上继续放宽内存访问限制,允许CPU以非FIFO来处理store buffer缓冲区中的指令。CPU只保证地址相关指令在store buffer中才会以FIFO的形式进行处理,而其他的则可以乱序处理,所以这被称为部分存储定序(PSO)。
宽松存储模型(relax memory order)(RMO模型)
为了榨取更多的性能,在PSO的模型的基础上,更进一步的放宽了内存一致性模型,不仅允许store-load,store-store乱序。还进一步允许load-load,load-store乱序, 只要是地址无关的指令,在读写访问的时候都可以打乱所有load/store的顺序,这就是宽松内存模型(RMO)。这里不再做详细展开了。
解决内存模型
芯片设计人员为了尽可能的榨取CPU的性能,引入了乱序的内存一致性模型,这些内存模型在多线程的情况下很可能引起软件逻辑问题。为了解决在有些一致性模型上可能出现的内存访问乱序问题,芯片设计人员提供给了内存屏障指令,用来解决这些问题。
内存屏障的最根本的作用就是提供一个机制,要求CPU在这个时候必须以顺序存储一致性模型的方式来处理load与store指令,这样才不会出现内存访问不一致的情况。
对于TSO和PSO模型,内存屏障只需要在store-load/store-store时需要(写内存屏障),最简单的一种方式就是内存屏障指令必须保证store buffer数据全部被清空的时候才继续往后面执行,这样就能保证其与SC模型的执行顺序一致。
而对于RMO,在PSO的基础上又引入了load-load与load-store乱序。RMO的读内存屏障就要保证前面的load指令必须先于后面的load/store指令先执行,不允许将其访问提前执行。
内存模型实现
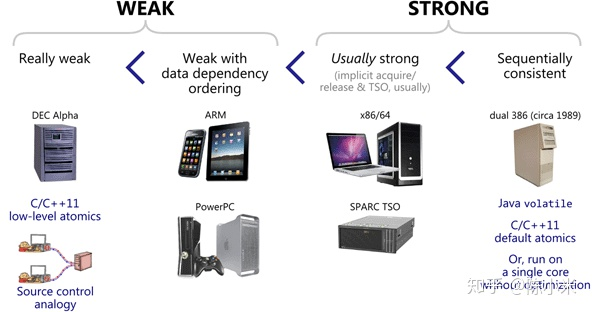
不同的处理器平台,本身的内存模型有强(Strong)弱(Weak)之分。实际实现的时候由于某些指令集之间的关系使得 memory barrier 的实现不可能做到最优,很多常见的平台都使用了简单粗暴的 bus 锁(x86、amd64、armv7)
Weak Memory Model(弱内存模型): 如DEC Alpha是弱内存模型,它可能经历所有的四种内存乱序(LoadLoad, LoadStore, StoreLoad, StoreStore),任何Load和Store操作都能与任何其它的Load或Store操作乱序,只要其不改变单线程的行为。
Weak With Date Dependency Ordering(Weak With Data Dependency Ordering): 如ARM, PowerPC, Itanium,在Aplpha的基础上,支持数据依赖排序,如C/C++中的A->B,它能保证加载B时,必定已经加载最新的A
Strong Memory Models(强内存模型): 最强的一致性,理想中的模型,在这种内存模型中,没有乱序的存在。如今很难找到一个硬件体系结构支持顺序一致性,因为它会严重限制硬件对CPU执行效率的优化(对寄存器/Cache/流水线的使用)。
你不太可能在现代多核处理器硬件内存模型中获得顺序一致性的保证。一般来说,你会在软件内存模型中寻求顺序一致性:如在java中使用volatile、在C++11中使用memory_order_seq_cst,这些高级编程语言会限制编译重排序以及发出特定CPU指令来限制内存重排序,以达到模仿顺序一致性的效果。
Strong Memory Model: 如X86/64,强内存模型能够保证每条指令acquire and release语义,换句话说,它使用了LoadLoad/LoadStore/StoreStore三种内存屏障,即避免了四种乱序中的三种,仍然保留StoreLoad的重排,
每个机器执行指令,默认地包含acquire、release语义。
这意味着,当某个cpu A执行一连串的写动作时,对于其他CPU,它们看到的写入顺序应该与A执行的一致。
x86 内存模型
x86/64系统架构提供了三种内存屏障指令:(1) sfence; (2) lfence; (3) mfence。
-
sfence ,实现Store Barrior 会将store buffer中缓存的修改刷入L1 cache中,使得其他cpu核可以观察到这些修改,而且之后的写操作不会被调度到之前,即sfence之前的写操作一定在sfence完成且全局可见;
-
lfence ,实现Load Barrior 会将invalidate queue失效,强制读取入L1 cache中,而且lfence之后的读操作不会被调度到之前,即lfence之前的读操作一定在lfence完成(并未规定全局可见性);
-
mfence ,实现Full Barrior 同时刷新store buffer和invalidate queue,保证了mfence前后的读写操作的顺序,同时要求mfence之后写操作结果全局可见之前,mfence之前写操作结果全局可见;
- Lock
Lock前缀,Lock不是一种内存屏障,但是它能完成类似内存屏障的功能。Lock会对CPU总线和高速缓存加锁,可以理解为CPU指令级的一种锁。它后面可以跟ADD, ADC, AND, BTC, BTR, BTS, CMPXCHG, CMPXCH8B, DEC, INC, NEG, NOT, OR, SBB, SUB, XOR, XADD, and XCHG等指令。
Lock前缀实现了类似的能力.
-
它先对总线/缓存加锁,然后执行后面的指令,最后释放锁后会把高速缓存中的脏数据全部刷新回主内存。
-
在Lock锁住总线的时候,其他CPU的读写请求都会被阻塞,直到锁释放。Lock后的写操作会让其他CPU相关的cache line失效,从而从新从内存加载最新的数据。这个是通过缓存一致性协议做的。
这里也引申出关于内存屏障的两个常用语义:
-
acquire语义:Load 之后的读写操作无法被重排至 Load 之前。即 相当于LoadLoad和LoadStore屏障。
-
release语义:Store 之前的读写操作无法被重排至 Store 之后。即 相当于LoadStore和StoreStore屏障。
对于x86架构来说,store buffer是FIFO,因此不会存在乱序,写入顺序就是刷入cache的顺序。但是对于ARM/Power架构来说,store buffer并未保证FIFO,因此先写入store buffer的数据,是有可能比后写入store buffer的数据晚刷入cache的。从这点上来说,store buffer的存在会让ARM/Power架构出现乱序的可能。store barrier存在的意义就是将store buffer中的数据,刷入cache。
在某些cpu中,存在invalid queue。invalid queue用于缓存cache line的失效消息,也就是说,当cpu0写入W0(x, 1),并从store buffer将修改刷入cache,此时cpu1读取R1(x, 0)仍是允许的。因为使cache line失效的消息被缓冲在了invalid queue中,还未被应用到cache line上。这也是一种会使得指令乱序的可能。load barrier存在的意义就是将invalid queue缓冲刷新。
对于x86架构的cpu来说,在单核上来看,其保证了Sequential consistency,因此对于开发者,我们可以完全不用担心单核上的乱序优化会给我们的程序带来正确性问题。在多核上来看,其保证了x86-tso模型,使用mfence就可以将store buffer中的数据,写入到cache中。而且,由于x86架构下,store buffer是FIFO的和不存在invalid queue,mfence能够保证多核间的数据可见性,以及顺序性。
对于arm和power架构的cpu来说,编程就变得危险多了。除了存在数据依赖,控制依赖以及地址依赖等的前后指令不能被乱序之外,其余指令间都有可能存在乱序。而且,它们的store buffer并不是FIFO的,而且还可能存在invalid queue,这些也同样让并发编程变得困难重重。因此需要引入不同类型的barrier来完成不同的需求。
我们接下来着重讨论 X86 平台下,Java volatile 关键字是如何实现防止指令重排序的。
这里不再展开,细节请参见Java并发编程之volatile关键字
参考
赞赏一下